OpenCog Hyperon:人間レベルを超えるAGI(汎用人工知能)のためのフレームワーク<後編>
OpenCog Hyperon(オープンコグ ハイペロン)の概要
2008年にリリースされたOpenCogは、ソフトウェアとハードウェアを組み合わせて心の働きをシミュレートするオープンソースプロジェクトであり、AGI(汎用人工知能)の実現を目指しています。脳を直接リバースエンジニアリングするのではなく、コンピュータ科学に基づいた工学的なアプローチを採用している点が特徴です。その認知アプローチは、心の哲学、認知科学、コンピュータ科学、数学、言語学など、多岐にわたる学術分野の融合に基づいています。
OpenCogは、Atomspaceと呼ばれる高度な知識グラフを中心に、ニューラルネットワーク、生成AI、確率的AI、プログラム学習AIなど、さまざまなAIモジュールを統合します。この統合により、適切な認知アーキテクチャを通じて異なる知能コンポーネントが相互に支援し合い、創発的な構造とダイナミクスを生み出す「認知的シナジー」を実現します。
また、OpenCogはオープンソースプロジェクトであり、誰でもコードを閲覧したり、貢献したりすることができます。
2021年に再構成されたOpenCog Hyperonは、OpenCogプロジェクトの拡張版であり、スケーラビリティと使いやすさの課題を解決し、新たな数学的概念を用いて、より強力で汎用性の高いAIの実現を目指しています。2024年4月30日には、Hyperonのアルファ版がリリースされており、最新のAI言語「MeTTa」を導入し、学習空間と知識ストアを提供することで、パターンマイニングや注意配分などのツール群を活用し、AIシステムが協調して学習し問題を解決することが可能になります。
Hyperonは、SingularityNET、HyperCycle、AI-DSLと協力し、全てのAIエージェントが互いに通信できるメタサービスの集合をサポートするフレームワークとして機能し、部分の総和よりも大きいAGIシステムを形成します。
参考文献
以下、2023年9月19日に発表された論文の後半部分になります。内容は正確性と読みやすさに配慮して行う予定です。
論文タイトル:『人間レベルを超える汎用人工知能のためのフレームワーク:OpenCog Hyperon: A Framework for AGI at the Human Level and Beyond』
注意事項
- 翻訳はLLMを用いて行うため、内容に誤りがある可能性があります。
- 翻訳結果については、専門家のレビューが必要です。
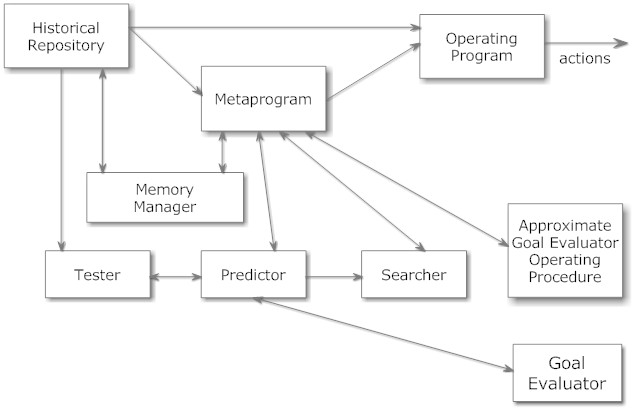
4. CogPrime認知モデル(そして更なる進化)
Hyperonソフトウェアフレームワークは、多様な認知アーキテクチャやAGIアプローチの実装に柔軟に適用できます。具体的には、ワンショット型質問応答チャットシステム、定理証明システム、さらには人間に類似した認知アーキテクチャの構築さえも可能にします。しかしながら、OpenCogの開発当初から中心に据えられ、Hyperon時代にも継承されている特定の認知アーキテクチャが存在します。本節では、この「歴史的デフォルトのHyperon認知アーキテクチャ」と、それに付随するいくつかのアイデアについて説明します。
最新のCogPrime認知モデルの詳細については、ゲーツェルの2021年の論文『汎用知能の一般理論:General Theory of General Intelligence』で最も包括的に解説されています。この論文には、他の関連する最近の技術論文への詳細な指針も含まれています。本稿では、数学的な説明を控え、よりハイレベルな視点から解説を行い、基本的なCogPrime認知モデルの概念を理解することを目的としています。ただし、基礎理論の深い理解を提供するものではありません。
4.1 CogPrime:Hyperonの歴史的デフォルト認知モデル
CogPrimeは、OpenCogプロジェクトの歴史を通じて中心的に追求されてきた、ある程度柔軟に定義された認知アーキテクチャです。2012年にOpenCog Classicの文脈で構築されましたが、現在でもHyperonの文脈で十分に機能します。このアーキテクチャは様々な出版物で「CogPrime」と呼ばれてきましたが、この名称は特に普及しませんでした。しかしながら、OpenCogをソフトウェアフレームワークとして、そこで実装される可能性のある特定の認知アーキテクチャと区別することは重要です。OpenCog Hyperonは、CogPrimeアーキテクチャのニーズに応えるために設計されたフレームワークですが、他の要件も考慮されています。したがって、HyperonがCogPrime以外のアーキテクチャを探索するために使用される可能性もあり、またHyperonでのCogPrimeを使用した実践的なAGI研究開発を進める中で、CogPrime自体も大きく進化する可能性があります。
CogPrimeの主要な参考文献は、2014年に出版された2巻組の書籍『汎用知能のエンジニアリング:Engineering General Intelligence , Part1 , Part2』です。CogPrimeの複雑さを少し簡略化すると、以下のようなことが行われています。
- 知覚形成:Atomspace内のアトムが形成され、これらはニューラル空間などの他の空間での表現とリンク付けられます。
- 行動生成:Atomspace内のアトムによって行動が構成され、その後、実行のために他の表現形式(例:ニューラル活性化パターン、Rholangプログラムなど)に変換される場合もあります。
- 周辺認知活動:Atomspace内では、重要度の伝播(アトム間での接続に応じて重要度が伝播する)、概念形成(既存のアトムから新しいアイデアを表す新しいノードを構築する)、推論(既存の関係から新しい関係を構築する)など、自律的で自己組織化された活動が発生します。これらは直接的に目標指向の方法で駆動される活動ではありません。
- 目標指向型活動:システムが現在の状況に対する認識に基づいて、目標達成の可能性が高いと考える行動を推論し、選択(合成)する活動です。
CogPrimeは、複数のMeTTaスクリプトで表現される複数の認知プロセスが連携して、これらすべてを実現します。正確な認知プロセスの組み合わせは現在も実験中であり、初期の非常に詳細な仮説は2014年に出版された『汎用知能のエンジニアリング』に記載されており、オンライン上でも簡潔にまとめられています。以下にそのハイライトを簡単にまとめます。
- ECAN(Economic Attention Allocation:経済的注意配分):アトム間の短期および長期の重要度を伝播させるためのメカニズムです。
- PLN(Probabilistic Logic Networks:確率論理ネットワーク):観測結果や自然言語、数学、その他のソースから得られた知識に基づいて、不確実な論理的結論を導き出すためのプロセスです。
- 概念混合:既存の証拠と既存の概念に基づいて新しい概念を形成するためのマッピング、オッカムの剃刀に基づく概念述語化など、ヒューリスティックなプロセスです。
- 進化学習:Atomspaceの新しいサブネットワークを、特定の基準を満たすように進化させるためのプロセスです。
- 確率的手続きと述語合成:Atomspaceやその他の空間にある確率分布に基づいて、新しいコンテンツを作成するためのプロセスです。
- パターンマイニング:Atomspaceや他の空間で観察されたパターンを表す新しい述語を生成するためのプロセスです。
- 目標の洗練:システムの上位目標に基づいて、サブゴールの作成、削除、統合を行うためのプロセスです。
- 目標駆動型のアクション選択:認識された状況下でシステムの目標達成に役立ちそうな行動を選択するためのプロセスです。
- オートポイエーシス(自己生成):相互に書き換えを行うことができるルールを活用して、オートカタライティックシステムを構築します。(OpenCogでは “Cogistry“とも呼ばれ、ある意味でAera認知アーキテクチャにおけるReplicodeの使用に似ています)
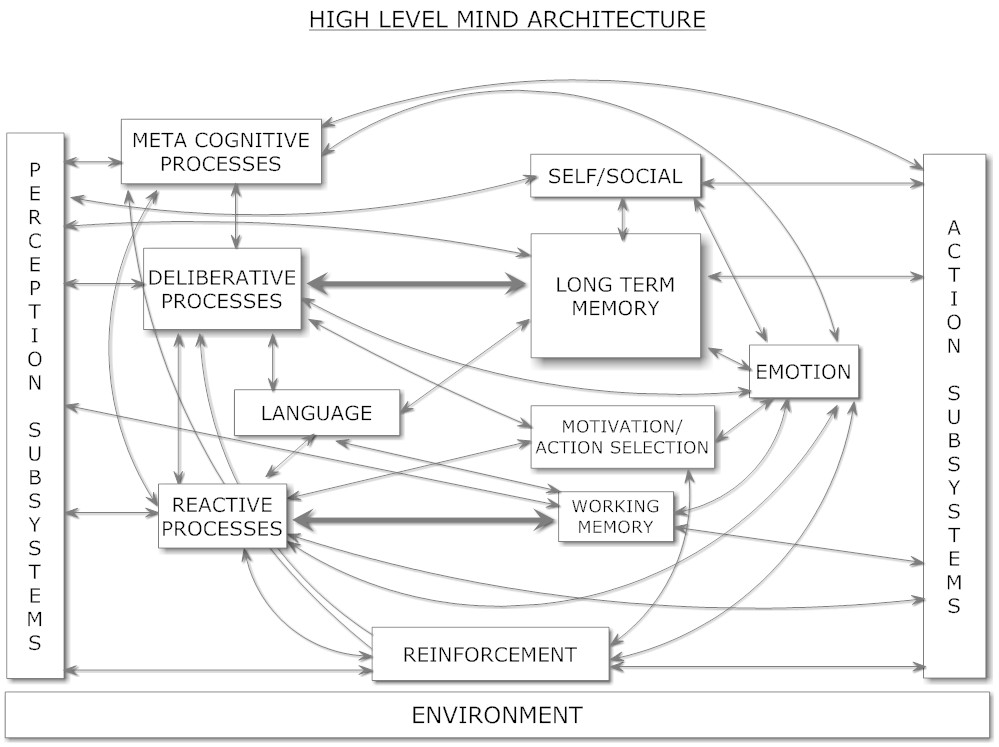
(汎用知能のエンジニアリングより引用)
Hyperonアーキテクチャでは、これらのすべてのプロセスがAtomSpaceを中心として実行されます。当初は手動でコーディングされたMeTTaが用いられ、その後、学習によって生成されたMeTTaコードが詳細を補完していきます。LLMは特定の機能に限定されず、補助的な役割としてさまざまななプロセスに関与します。例えば、LLMは言語に関して大きな役割を果たす可能性がありますが、長期記憶の複数の形式の一つとして機能することもあります。また、LLMは反応的プロセス(即時的反応)と熟考的プロセス(計画的行動)の両方において情報源として機能することができますが、どちらの場合も限界があるため、他の推論プロセスや学習プロセスと連携させる必要があります。
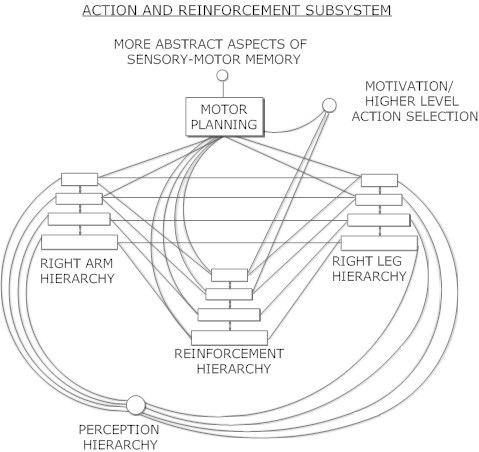
(汎用知能のエンジニアリングより引用)
現在の技術を使用してこれを実装する方法の一つは、深層ニューラルネットワークを行動(例:右腕と左腕)と強化階層に活用し、AtomspaceベースのMeTTa手続きを運動計画の主要モダリティとして使用することです。ここで重要なのは、MeTTaのシンボリックな行動計画とニューラルネットの運動合成能力との間の流動的な連携です。単にMeTTaが高レベルの計画を出力し、ニューラルネットがその高レベル計画の各行動を個別に実行する方法では不十分です。むしろ、高レベルの計画全体をニューラルネットが文脈として捉え、その計画の各部分に対応する行動の合成を行う必要があります。これにより、全体の動作系列を反映した形で各サブアクションの運動が詳細に実行されることが可能になります。
これは、Neural-Symbolic統合を探求するための素晴らしいユースケースであり、Hanson Robotics、Awakening Health、Mind Children、その他の共同プロジェクトとの連携を通じて、実世界のロボット工学の文脈で探求していく予定です。このような目的のためにオープンなロボット工学コミュニティが、Hyperonをカスタマイズすることにも関与することが望ましいです。
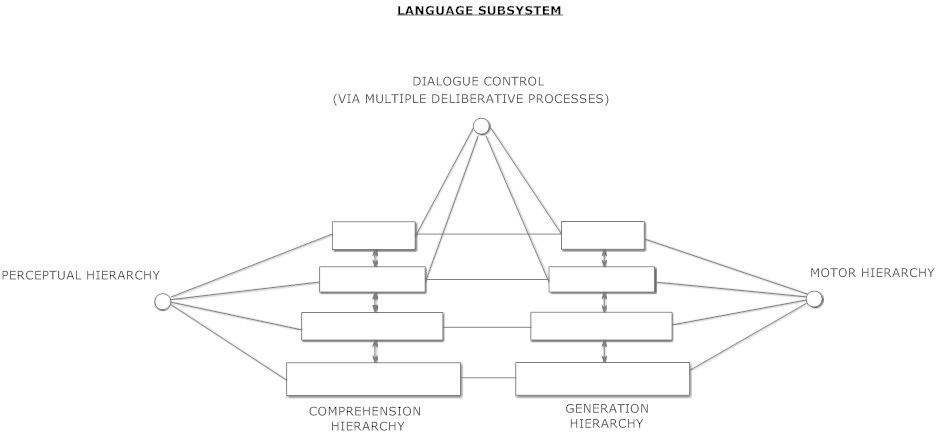
(汎用知能のエンジニアリングより引用)
トランスフォーマー型ニューラルネットワーク(LLMなど)は、結合された理解と生成の階層構造を実装する非常に効果的な手法の一つです。この二つの階層は、分離されてから密接に連結されるというよりも、密接に相互浸透しています。シンボリックなパターン認識と推論が、LLM内の内容に対応する(確率的または明確な)形式的な言語規則の認識に用いられるならば、推論された規則もまた階層構造に自然に配置されると考えられます。そして、理解側と生成側の両方で同じ規則が使用されることになるでしょう。
言語にとって知覚、行動、認知との密接な連携は明らかに重要であり、現在のLLMでは過小評価されていると言えます。LLMの幻覚(ハルシネーション)の対策の一つは、確立された真実を含む知識グラフとLLMを推論的に接続することですが、LLMを直接的な知覚や活動的な基盤と接続することも、LLMのパターンと非言語的現実との必要な接続を提供するもう一つの有効な方法です。
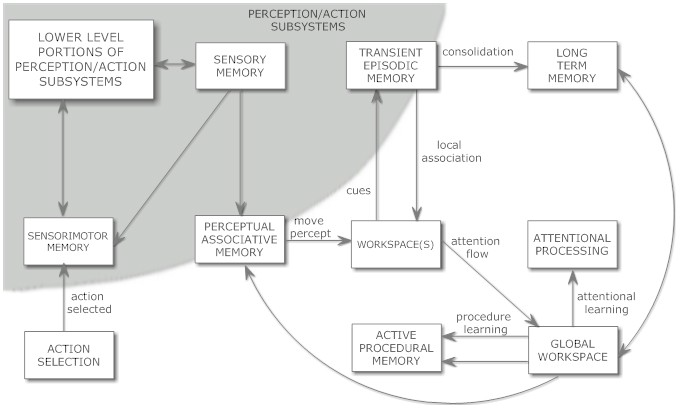
(汎用知能のエンジニアリングより引用)
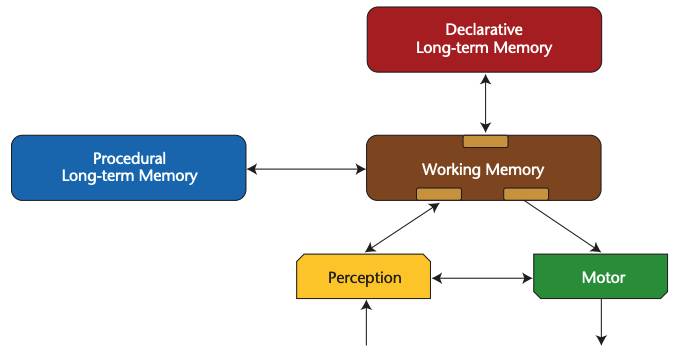
Hyperonでは、これらのコンポーネントの大半はAtomspace内に実装されており、それらが「ワーキングメモリ(作業記憶)」に記憶されるかどうかは、短期重要度(Short-Term Importance)の値が一定の閾値(注意焦点境界)を超えているかどうかによって決定されます。連想記憶は、Atomspaceのハイパーベクトル埋め込みによって効率的に実装できます。感覚、感覚運動、行動、言語記憶などの側面は、ニューラルネットワークやその他のサブシンボリックなコンポーネントに記憶されることもありますが、これらの側面も柔軟な操作のために記号形式で表現されることが重要です。
この図は、以下のグローバルワークスペース理論のダイナミクスを模式的に示唆していますが、Hyperonでは注意焦点内のアトムと外部のアトム間で重要度の値が伝播することで表現されます。このプロセスはECAN(経済的注意配分)方程式に基づいています。
- 意識は計算可能である:グローバルワークスペース理論におけるLIDAモデル:Consciousness is computational:The LIDA model of global workspace theory
現在のLLMは、十分に構造化されたワーキングメモリを欠いており、これが人間同士の認知エージェントとの対話というよりも、ユーティリティ(道具)と対話しているように感じる一因となっています。多くのプロジェクトでは、LLMのダイナミクスと連携する様々な種類の外部的なワーキングメモリを構築することで、LLMベースの対話型キャラクターの開発を試みています。しかし、ワーキングメモリがその役割を果たすためには、かなり柔軟なシンボリック表現が必要となります。なぜなら、ワーキングメモリの内部で行われるべきことの一つは、その中に含ま れる異なる項目を多様な方法で変化させたり組み合わせたりすることだからです。効率的で柔軟な操作は、ほぼ「シンボル性」と同義であると言えます。
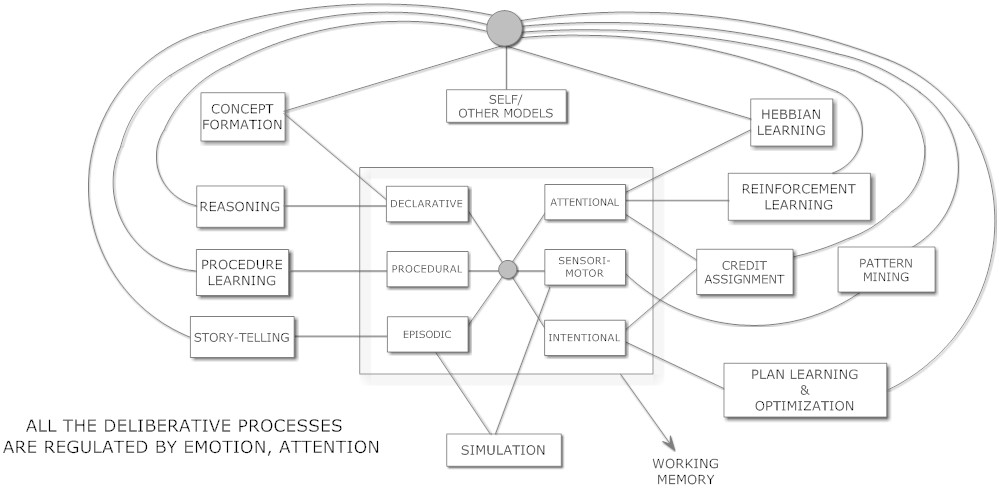
(汎用知能のエンジニアリングより引用)
Hyperonにおいて、Atomspaceはまさにその機能の中核を担う存在です。様々な種類の知識を長期的に保持するメモリとして機能し、それらを共有されたメタ表現基盤(型付きメタグラフノードとリンクで構成)に基づいて処理します。さらに、この図で示唆された役割を果たす認知プロセスを実行するための手順も保存し、認知機能全体を支える基盤となっています。
多くの場合、同じHyperonアルゴリズムが、ここで示される機能の一部または全部を完全に実行できます。例えば、PLNは、推論、手続き学習、ストーリーテリング、強化学習、信用割り当て、計画立案を支援できます。一方、進化学習は、手続き学習、強化学習、概念形成を支援できます。
ここで示されている多くの機能は、Hyperon内で複数の同時実行プロセスや協調プロセスによって実行されます。例えば、概念形成は、進化学習、概念ブレンディング、形式概念分析(パラ整合不確定)、またはその他のさまざまなヒューリスティック手法によって行われる可能性があります。
人間のような認知を実現するためには、これらのすべてのプロセスが、同じ大規模なAtomspaceメタグラフ上で同時に実行される必要があります。これにより、自己モデルや能動的な自己修正型の概念階層・異階層といった大規模な心の構造パターンの出現につながる認知的シナジーが生み出されます。
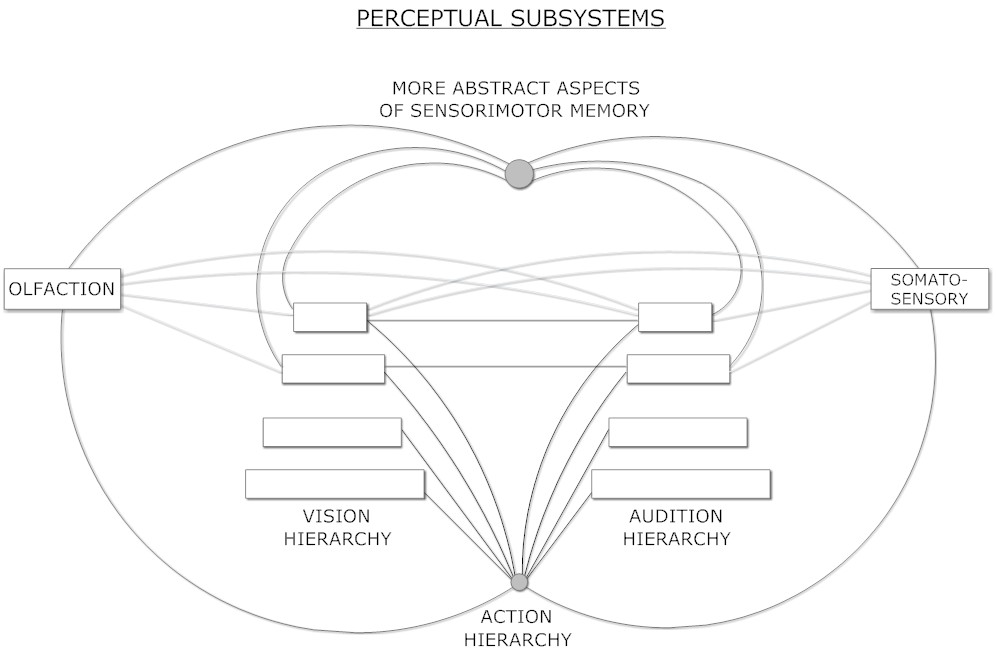
(汎用知能のエンジニアリングより引用)
現代のAIの世界では、視覚や聴覚などの知覚処理は、大規模なコーパス上で訓練された階層型ニューラルネットワークによって、多くの点で効果的に行われています。しかし、これらの階層を、感覚データの構成的構造を明示的に表現するAtomspace内のシンボル階層と連携させることで、より高度な知覚理解を実現できると考えています。
本質的に、嗅覚と体性感覚の知覚はあまり階層的ではありません。実際、ヒトの大脳皮質における嗅覚パターン認識は、非線形ダイナミクス、ストレンジアトラクタ、または一時的なパターン形成に基づいているという証拠があります。これらの知覚をニューラルネットワークモデルで再現することは可能ですが、現時点では成熟した形で実現されていません。このように全く異なる組織構造を持つ感覚知覚を低レベルで相互に結びつける点で、シンボルによる理解はより価値があるかもしれません。特に、はるかに多様な感覚チャネルを持つ可能性のあるAGIにおいては、この傾向はさらに顕著になるでしょう。
これらはすべて、MeTTaベースのAtomspace内で動作するプロセスです。その後、ニューラルスペースやその他のリソースと相互運用することができます。
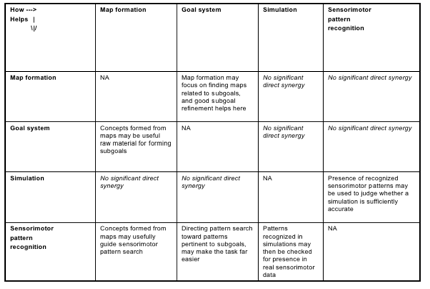
図6、7、8、9、10、11は、CogPrime認知モデルに基づいて人間レベルの汎用知能機能の実現に関わる主要なコンポーネントをまとめています。これらの認知コンポーネントとソフトウェアコンポーネントの関係は少し複雑です。一部は特定のソフトウェアプロセスに直接対応していますが、多くは複数のOpenCogソフトウェアプロセスによって実現されることを想定しており、同じOpenCogソフトウェアプロセスが複数の機能の基盤となる場合もあります。例えば、Hyperon Atomspace(ソフトウェアコンポーネント)は、宣言的記憶と手続き記憶(認知コンポーネント)の両方に使用されます。自然言語理解は、LLMとPLNのようなAtomspaceネイティブなプロセスの組み合わせによって実現される可能性があります。『汎用知能のエンジニアリング』で提示されているCogPrime AGI設計には、直前の箇条書きリストで挙げたAIプロセスを中心に、特定のAIプロセスセットを使用してこれらの様々な認知機能をどのように達成するかについての詳細な理論が盛り込まれています。
認知アーキテクチャを箱と線の図で示すのは便利ですが、もちろん認知の真髄の多くは、さまざまな箱の内容間の相互作用と相互依存関係によって生み出されます。CogPrime設計の基盤となる重要概念である「認知的シナジー」も、まさにこの視点に立脚しています。これは『認知的シナジーの形式的モデルに向けて』にて、形式的に豊穣圏を用いて定義されていますが、直感的には非常にわかりやすいものです。つまり、 各種の認知プロセスが互いに協力して働くという意味で、例えば、あるプロセスが処理を進める中で行き詰った場合、その中間状態を他の認知プロセスの「ネイティブ言語」に変換し、助けを求めることができます。図12、13、14、15は、すべて『汎用知能のエンジニアリング』から引用されており、CogPrimeアプローチを用いた高度なAGI実現に不可欠と考えられる、特定の認知プロセス間のシナジーの一例を示しています。
4.2 汎用知能の一般理論に向けて
ゲーツェルの2021年の論文『汎用知能の一般理論(GTGI)』は、直近の以下の複数の研究論文を基に、CogPrimeアーキテクチャの中核概念を統一されたエレガントな数学的枠組みで定式化することを試みています。これは、関与する多様な記憶、学習、推論メカニズムの根底にある重要概念を明らかにし、高度に効率的でスケーラブルな実装をより容易にすることを目指しています。
- 認知のパターン:確率論的型を持つメタグラフ上でのクロノモーフィズムによって実現されるガロア接続としての認知アルゴリズム:Patterns of Cognition:Cognitive Algorithms as Galois Connections Fulfilled by Chronomorphisms On Probabilistically Typed Metagraphs
- 認知的シナジーの形式的モデルに向けて:Toward a Formal Model of Cognitive Synergy
- メタグラフにおける折り畳みと展開:Folding and Unfolding on Metagraphs
- 形式的単純性理論に基づいたオッカムの剃刀の基礎付け:Grounding Occam’s Razor in a Formal Theory of Simplicity
GTGIアプローチは、人間のような認知機能に関わる様々な種類の記憶を、型付きメタグラフ内の異なる型システムとして表現できるという概念をより精密に定式化します。さらに、これらの異なる型システムに対応するカテゴリー間でモルフィズムと呼ばれる数学的な関係を定義します。また、ある程度の近似において、人間のような認知に必要な様々なタイプの記憶に対応するコアアルゴリズムは、ガロア接続を通じて、メタグラフ上でのさまざまな「折り畳み」と「展開」と呼ばれる種類の操作として表現できると主張しています。このことから、階層的知覚や行動学習、論理的推論、進化プログラム学習など、一見異なるような認知プロセスも、大きなメタグラフ上で適切な折り畳みと展開を行う効率的な基盤があれば、すべて効率的に実装できる可能性が示唆されます。こうした考察とその他の洗練されたバリエーションは、MeTTa言語の基本設計に大きな役割を果たしました。MeTTa言語は、これらのメタグラフ操作を適切に抽象化し、スケーラブルに実装できるインフラストラクチャを提供します。
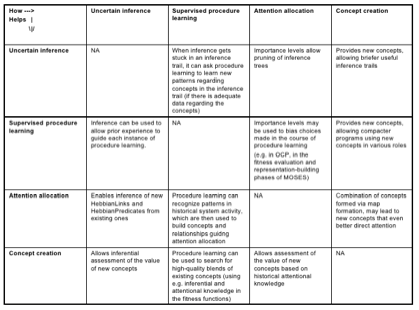
(汎用知能のエンジニアリングより引用)
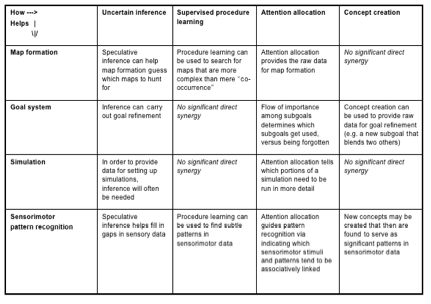
(汎用知能のエンジニアリングより引用)
(汎用知能のエンジニアリングより引用)
4.3 Hyperon、CogPrime、そして(人間のような)標準心モデル
上記で述べたように、HyperonとCogPrimeによる認知アプローチは、心の哲学、認知科学、コンピュータ科学、数学、言語学などの多岐にわたる学術分野の融合から生まれました。その基盤となる理論体系は非常に豊富で多様なため、ここで全てを要約するのは困難です。しかし、説明を続けるために話を単純化すると、この認知活動を考察する一つの有用な方法は、人間の心についての知見と比較すること、つまり認知科学の観点から焦点を当てることです。
本稿では、CogPrimeの包括的な分析を行うことはできません。なぜなら、図6、7、8、9、10、11で示されている全てのプロセスとその主要なサブプロセスを網羅しようとすると、この概説の範囲を超えてしまうからです。そのような分析は、まさに『汎用知能のエンジニアリング, Part2』の主題となっています。より簡潔で情報量が少ないアプローチとしては、いわゆる「標準心モデル」のような人間の認知を簡略化したモデルを検討する方法があります。
Paul Rosenbloomと長年の認知アーキテクチャ研究コミュニティのメンバー達は(近年の主要潮流が深層ニューラルネットワークに移行する以前は、AI研究コミュニティの中でも大きな勢力を占めており、現在も学術研究分野で活発に活動しています)、数多くの経験的、理論的な知見を統合して「標準心モデル」と呼ばれるものを構築しました。図16はその概要を示していますが、細かい部分については議論の余地があるかもしれません。しかしながら、認知心理学、認知神経科学、AI研究など、多様な分野から得られた人間型認知理解の共通要素を統合し、まとめるという試みは、野心的で価値があり、一定の成果を上げたと言えるでしょう。Hyperonの認知アプローチを標準心モデルで特定された様々なコンポーネントと比較することは、非常に興味深い試みです。
標準心モデルの簡単な概要は、ベン・ゲーツェルの最近の論文『生成AI vs. AGI:Generative AI vs. AGI』で簡潔に説明されているため、ここでは繰り返しません。同論文では、標準心モデルが特定する主要なコンポーネントに基づいて、LLMの長所と短所についても概説しています。現時点では、LLMもHyperonも標準心モデルで定義されたすべての側面で優れているわけではありません。また、現在のLLMの性能と仮説上のHyperonの将来的な能力を比較することは適切ではないことも理解しています。しかしながら、多くのLLMの短所を標準心モデルに対して改善することは、根本的なアーキテクチャの修正と追加が不可欠であるという強い直感を持っています。この直感は根拠に基づいており、妥当性があると考えています。一方、Hyperonはすでにコアアーキテクチャに標準心モデルのすべての側面と、さらなる機能を満たす能力を備えています。
それでは、標準心モデルの主要コンポーネントを順に見ていき、それらがHyperonとCogPrimeの認知設計でどのように扱われているかを説明します。
4.3.1 エピソード記憶
エピソード記憶は、エージェントの生涯における出来事や体験に関する記憶です。CogPrimeでは、「エピソードインデックス」と呼ばれる特別な仕組みによって、Atomspaceや感覚記憶を格納するニューラルスペースなどの他の記憶領域と関連付けられています。このエピソードインデックスの特徴は、以下の5つの種類のクエリを効率的に処理するために設計されています。
- 類似項目検索:特定の手掛かりに似た項目を検索します。
- 部分一致検索:部分的に完成した手掛かりと一致する項目を検索します。特に、欠けている部分と物理的または時間的に関連する要素を含む補完が求められる場合。
- 物理的関連性検索:手掛かりと何らかの時点で物理的に関連していた項目を検索します。
- 同時発生検索:手掛かりと同じ時間に発生した項目を検索します。
- 空間的関連性検索:手掛かりと同じ場所、またはその近くの場所で発生した項目を検索します。

これらの種類のクエリに適したインデックス構造を作成する実用的な方法の一つとして、ハイパーベクトル(大規模な疎ビットベクトルまたは整数ベクトル)を使用する方法があります。ハイパーベクトルは1980年代にPentti Kanervaによって提唱されましたが、他の多くの古典的なAI理論と同様に、現代の膨大な計算能力とデータの利用可能性によって、ようやくその概念的な可能性が現実のものとなりつつあります。
このアプローチでは、Hyperonインスタンスはハイパーベクトルストアを持ちます。このストアには、Atomspace内のアトムのハイパーベクトル埋め込みと、場合によってはニューラルスペース内のニューラルネットにおける観測された活性化パターン(ニューロンの発火)のハイパーベクトル埋め込みが格納されます。
ハイパーベクトルを用いたアプローチには、ハイパーベクトルを使用したクエリ処理をGSIのAPUチップ(現在実験中)や、Simuliのハイパーベクトルチップ(現在プロトタイプ段階)上で効率的に実装できるという付随的な利点があります。
4.3.2 ワーキングメモリ
CogPrimeで使用されるHyperon Atomspaceにおけるワーキングメモリは、基本的に短期重要度(STI)が十分に高いアトムの集合体で構成されています。ECANのダイナミクスは、特定の閾値を超えるSTIを持つアトムを「注意焦点」と見なし、異なるECANパラメータが適用されます。これにより、様々な認知プロセスが設定され、注意焦点からアトムを選択して様々な目的を果たしたり、残りのAtomspaceからアトムを選択して別の目的を果たすことができます。
アトムの注目焦点とAtomspaceの残りの部分との間の移動も、ECANのダイナミクスによって制御されており、強迫性障害や散漫さなどの病理状態を回避しつつ、システムを適切な注意状態に維持するように調整されます。この点に関して、OpenCog Classicでは以下のような多数の実験が行われました。
- 非線形ダイナミック注意割り当てによる確率論的論理推論のガイド:Guiding Probabilistic Logical Inference with Nonlinear Dynamical Attention Allocation
- 読書における注意のシフトとドリフト:OpenCog認知アーキテクチャにおける非線形ダイナミック注意割り当ての事例研究:Shifting and drifting attention while reading: A case study of nonlinear-dynamical attention allocation in the OpenCog cognitive architecture
- 非線形ダイナミック注意割り当てを用いた推論における組合せ爆発の制御:Controlling Combinatorial Explosion in Inference via Synergy with Nonlinear-Dynamical Attention Allocation
SingularityNETのチーフAIオフィサーであるMatt Ikleは、1990年代後半から様々なAIシステムでECANのバリエーションに取り組んできました。彼は、この種のシステムダイナミクスについて次のようにまとめています。
進化型汎用知能を目指すあらゆるシステムにとって、計算資源の割り当ては重要な課題の一つです。Hyperonの注意割り当てシステムは、経済的注意ネットワーク(ECAN) モジュールによって実現されています。経済学のメタファーに基づいて設計されたECANは、汎用人工知能を達成するために必要と考える自己組織的な高次ネットワーク構造の創発を促進する重要な要素です。
ECANは、型を持たないノードと、HebbianLinkと呼ばれる型を持つリンクで構成されたグラフです。各アトムには、短期重要度(STI)と長期重要度(LTI)の2つの値が重みとして割り当てられています。ECANでは、STIとLTIの値を人工通貨として扱う方程式系を用いて、重要度の更新が行われます。この方程式は、現在の目標達成に関連するアトムの役割の重要度に基づいて、システム内のアトム間で重要度を伝播させます。ECANにおける重要な概念は注意焦点で、これはシステムが現在の目標達成のために最も重要と判断したアトムの集合で構成されています。ECANをHyperonフレームワークに移植する際には、速度と効率の向上を目的とした機能強化を活用します。その一例として、自然勾配(確率分布上の勾配)を用いて、パラメータ空間の損失関数の空間で最も急な減少方向を追跡する方法です。初期の実験では、このアプローチにより、劇的な処理速度と精度の向上が見られました。
また「単純で安定した構成要素から複雑さが生じる」というプロセスを導くための、いくつかのアルゴリズムとアーキテクチャの改良も検討しています。Hyperonの複雑なダイナミカルシステムに関するセクションでより詳しく説明されているように、観測された自然の力学系に沿ったウェイポイントを構築することを構想しており、これにより、望ましい出現現象が複数のスケールで生じるように開発を促します。また、トノーニのΦ(ファイ)のような、知覚や意識に関連していると考えられる尺度を用いた実験も計画しています。
- 認知システムにおける読書や会話中の意識状態をトノーニのΦで測定する:Using Tononi Phi to Measure Consciousness of a Cognitive System While Reading and Conversing
4.3.3 手続き記憶(Procedural memory)
Hyperonにおける手続き記憶は、基本的にはMeTTaプログラムで構成されています。しかし、MeTTaは本質的にメタ言語であり、異なる型システムをMeTTaに実装することで、様々なプログラミング言語を「模倣」させることができます。特に、論理プログラミングや関数型プログラミングのパラダイムが最も自然に表現できます。この機能を活用することで、数学の定理を証明するための認知的ヒューリスティック、ロボットの運動制御手順、自然言語対話のフローを制御する手順など、様々な種類の処理を、異なるMeTTa型システムで表現されたサブ言語で実装することが可能です。これらの型システムは、最初は人間プログラマーによって実装されますが、MeTTaの反射的な性質により、システム自身の学習と推論を通じて型システムが生成されることも自然なことです。
認知的に意味のある手続き表現においては、適切な抽象化が不可欠な役割を果たします。人間のような認知に関わる手続き知識は、曖昧かつ不確実な場合が多く、直感的な推論に基づいて、特定の文脈に応じて具体的なプロセスとして具現化される高階層のプロセスで構成されています。言い換えると、手続き実行には、単純なMeTTaプログラムの実行だけでなく、曖昧で抽象的なアトムネットワークを直接実行可能な具体的なMeTTaプログラムに変換する、より高度な認知プロセスを伴う場合があるということです。
多くの場合、一般的な手続きを表現する曖昧で抽象的なアトムネットワークは、時間的または因果関係を表す特別なアトムタイプを活用します。近年、AtomSpace上での時間的推論に関する重要なプロトタイプの開発が進められており、例えば、Minecraftでの単純なエージェントの制御やPongなどのゲームプレイといった具体的な応用例が示されています。
手続き知識と宣言的知識の変換は、プログラムと論理式の間にカリー=ハワード同型対応のような関係(例:Greg MeredithのOSLF)を用いて行われます。
4.3.4 推論(Reasoning)
Hyperonのインフラストラクチャーは、形式的推論システムを幅広くサポートします。例えば、異なる論理体系は、それぞれ異なるMeTTa型システムで容易に表現できます。さらに、不確実性の扱いについても、ファジィ真理値代数に加えて、一次確率、高次確率、およびそれらの近似値を含む様々な手法に対応しています。
中でも特に注目されているのが、PLN(確率論理ネットワーク)と呼ばれる不確実性推論フレームワークです。これは、高次ファジ推論と確率推論を、述語論理や項論理と統合し、さらに人間認知をモデル化した内部構造に基づく推論と因果推論のアプローチを取り入れています。この形式論は、認知エージェントの観察結果に基づいて論理知識を明示的に導き出すものです。
PLN(および他の論理推論システム)にとって、最大の課題は常に推論制御でした。推論制御とは、どのような文脈でどの論理推論ステップを実行するかを選択するプロセスを指します。この課題に対処するためには、様々なヒューリスティックを用いることができますが、本質的なアプローチは反射的で履歴に基づいたものであるべきだと考えています。
基本的な推論の流れは以下の通りです。
- 単純な推論タスクでの推論の実行:まず、単純な推論タスクに対していくつかの基本的な推論ステップを実行します。
- パターンマイニングによる推論戦略の発見:次に、これらの単純な推論タスクにおける成功事例を分析し、どの文脈でどの推論ステップの組み合わせがうまく機能したかをパターンマイニングによって特定します。
- 抽象原理の抽出:パターンマイニングの結果から、どのような抽象的な原理が効果的な推論戦略を導いているのかを解明します。
- 新しい推論ステップの合成:パターンマイニングと抽象原理の抽出を活用し、新しい問題に対する新たな推論ステップの組み合わせを合成します。これにより、システムは徐々に複雑な推論タスクにも対応できるようになります。
- より複雑な推論への発展:以上の過程を繰り返すことで、システムは徐々に推論能力を向上させ、より複雑な問題に対しても適切な推論を行うことができるようになります。
このアプローチは概念的には単純ですが、成功するためには膨大な規模が必要です。これは、Hyperonの研究開発の次のフェーズにおける重要な課題であり、長年存在してきたAIアプローチが、十分なデータと処理能力を与えられることで真価を発揮する好例となる可能性を秘めています。
Nil Geisweillerは、OpenCog Classicと最近のHyperonの両方におけるPLNのリード開発者兼研究者であり、MeTTaでのPLNの現状を以下のようにまとめています。AGIを目指す推論システムは、少なくとも以下の2つの機能を備えていなければなりません。
- 柔軟性(チェーンニング):推論過程は、あらゆる方向に推論ツリーを生成できる必要があります。具体的には、前進推論(公理から定理へ)、後退推論(定理から公理へ)、外向推論(補題から公理や定理へ)、内向推論(公理や定理から補題へ)、そして一般的には全方向推論(公理、定理、補題、系定理など、相互間での推論)です。
- プログラマブル(推論制御):連鎖中に発生する任意の計算ステップは、十分な粒度で制御できるようにする必要があります。これにより、適切なヒューリスティック知識 があれば、成功する推論の生成を任意に効率化することができます。
HyperonとMeTTaを用いた初期の実験では、最初の機能である「柔軟性」の実現に向けて非常に有望な成果が得られています。MeTTaが持つ非決定性と統一という特性を活かし、わずか数行のコードで「全方向探索型チェイナー」のブルートフォース検索を実装することに成功しました(AGI-23会議録)。このチェイナーは、現在開発中のPLN移植版の基盤エンジンとして活用されています。今日では、OpenCog Classicでは実現できなかった直接証拠ルールの逆方向実行などもすでに可能になっています。これらの成果から、HyperonとMeTTaは柔軟性の要件を完全に満たしていると言えるでしょう。
次に「プログラマブル」な推論制御の要件は、minimal-MeTTaが完成すれば実現される見込みです。これにより、人間や機械プログラマーが簡約化ステップ(ベータ簡約など)を上書きし、非決定論的な簡約を剪定したり、優先順位付けするための条件分岐を挿入することが可能になります。
Geisweillerは、Hyperonにおけるパターンマイニングについて、ソフトウェアだけでなく数学的、概念的な側面からも「特殊な制御構造を持つ推論の一種」として捉えるべきだと主張しています。これは非常に興味深い視点であり、パターンマイニングと推論の深いつながりを明らかにするものです。
実際、パターンマイニングが特殊な推論形式として捉えられることは、すでに『汎用知能のエンジニアリング, Part2』で確立されています。このような視点を採用する利点は、単純な構文ベースのパターンマイニングと、高度なセマンティックベースのパターンマイニングを自然かつシームレスに統合できる点です。さらに、単純な推論と高度な推論の両方で推論制御を活用し、効率を高めることができるという追加の利点もあります。現在、HyperonとMeTTaのチェイナーを用いた概念実証が進められています。
PLNとMeTTa研究におけるさらなる興味深い展開として、PLN表現のセマンティクスとMeTTaの内包表記の利用との関連性が挙げられます。Greg Meredithが指摘するように、内包表記は、PLNに対する実現可能性に基づくセマンティクスを具体的に実装する手段として用いることができます。このセマンティック的アプローチと、Warrellの分析で示唆されているような高次確率型によるPLNセマンティクス表現とのつながりは、有望な研究テーマと考えられます。
- 確率型と非有基型型システムの同値性を検証するためのメタ確率プログラミング言語:A meta-probabilistic-programming language for bisimulation of probabilistic and non-well-founded type systems
明示的論理 vs. LLM推論
ここでPLN推論とLLM推論の関係について、若干の注意が必要です。現時点では、LLMはインターネット上に豊富に存在する知識領域において、人間並みの常識に基づく幅広い推論を処理できるようです。しかし、純粋な形式的な推論や、形式的なものと常識的なものを繋ぐような推論(例:学部レベルの物理学や経済学の問題)には全く対応できません。また、LLMが訓練に使用されたインターネット上のデータと根本的に異なる特性を持つ領域を一般化することも困難です。現在検討されているLLMとHyperonの統合アプローチは、日常的な常識に基づく推論に関してはLLMの強みを、より汎用的な推論に関してはPLNの強みを活用し、両者を自然な方法で結合させることを目指しています。このようなアプローチは、例えば物理学や経済学の問題を克服するための実用的で比較的迅速な道筋になるだけでなく、さらに野心的な汎用知能への道筋にもなると信じています。
このアプローチは、LLMがなければPLN自体では完璧な常識的推論を行えないことを示唆しているわけではありません。むしろ、PLNは十分な常識的推論能力を備えていると確信しています。しかし、現行もしくは改良型のLLMを活用することで、より常識的推論への効率的な道が開ける可能性があると期待しています。その理由は、常識的推論は科学的・数学的推論とは異なり、斬新かつ独創的な推論手順を連鎖させることよりも、過去の類似状況における妥当性を見つけ出すことに重点が置かれているからです。
LLMの推論チェーンをPLNの推論チェーンにマッピングし、PLNを導く推論パターンの学習データとして使用することも非常に興味深い方法です。このアプローチは、LLMが苦手とする形式的推論には限られた効果しかありませんが、形式的推論と常識的推論が混在する領域において、 PLNを適切に導く手助けとなる可能性があります。
空間と時間に関する推論
OpenCog Classicの研究開発における推論の一側面として、空間と時間に関する推論には多大な労力が注がれてきました。AGI研究者のHedra Seidは、次のように述べています。
空間的推論と時間的推論は、私たちが周囲を理解し、未来を予測し、変化の激しい現代社会で適切な判断を下すために不可欠な認知能力です。人工知能(AI)は、汎用人工知能(AGI)の実現を目指して進化を続けており、人間の認知機能を模倣する分野において目覚ましい進歩を遂げてきました。中でも、空間的推論と時間的推論は、周囲の状況を把握し、将来の出来事を予測する上で重要な役割を果たします。このような観点から、Hyperonは以下の理由から、そのような推論エンジンを構築するための有力な候補であると考えられます。
- 構造化された知識表現
- Hyperonは、概念、事実、関係、ルールを表現するための構造化されたフレームワークを提供します。
- 空間情報(オブジェクトの配置や向きなど)、時間的シーケンス(因果関係チェーンやイベント順序など)、そして一般的な知識の関連性を正確に捉えることができる豊かで表現力のある言語を提供します。 これにより、複雑な詳細情報を含むさまざまな推論タスクに適しています。
- 型駆動開発
- Hyperonの型駆動アプローチは、構造化されたコーディングを推奨します。
- 型は知識表現の開発を導き、構造化された、読みやすく、保守しやすいコードを促進します。
- コンパイル時に型関連の問題を特定することにより、実行時エラーを削減します。
- 型は値に依存できるため、表現力豊かな型を作成でき、イベントの重複やシーケンスなどのプロパティの証明を容易にします。
- スケーラビリティ
- Hyperonの分散型Atomspace(DAS)は、大規模な知識表現を処理するように設計されており、特に広範なデータセットと複雑な相互作用を伴う空間的推論と時間的推論に対して有利です。
PLNの空間的および時間的推論の能力は、最近ROCCAプロジェクトの文脈で開発されました。このプロジェクトは、PLNを使ってシンプルな環境でシンプルな目標を達成する単純なエージェントを制御することに焦点を当てており、強化学習の実験に使用されるおもちゃのような世界に似ています。これらのツールは、Hyperonの開発が進むにつれて、Sophiaverseのようなより野心的な仮想世界、ロボットの物理制御、そしてHyperonフレームワークのスケーラビリティの恩恵を受ける、さまざまな他の設定でも適用されるでしょう。
技術的問題解決におけるハイブリッド型アプローチの実現
LLMは、さまざまな種類の常識的推論や、米国のロースクールの入学試験のような特定の試験では、かなり有能であることが証明されていますが、大学レベルの理系試験ではパフォーマンスがあまり芳しくありません。Google Minervaシステムは、この目的のために微調整されていますが、マサチューセッツ工科大学(MIT)のオープンコースウェアから収集された以下のような問題での正解率は、報告によると約30%程度にとどまっています。
問題 1:マゼラン望遠鏡は2台あり、それぞれ直径は6.5メートルです。ある観測設定では、有効焦点距離は72メートルです。観測時の惑星の角直径が45秒角である場合、この焦点での惑星の像の直径(cm)を求めてください。
問題 2:1990年初頭、100匹のフェレットが大きな島に放されました。フェレットの最大自然増加率(𝑟max)は1.3年⁻¹ です。島には資源が無限にあるものとし、フェレットが数百年間生きられる十分な餌があると仮定します。この島には2000年までに何匹のフェレットがいるでしょうか?
これらの問題は、特別な学習を積んでいない一般の人にとっては明らかに簡単ではありません。しかし、関連するテキストを読み、宿題に取り組んでいる典型的な理系学生にとっては、非常に理解しやすいものです。直感的に、これらの問題を解く際には4つの要素が関わってきます。
- 英語力と常識理解:問題文を理解し、背景知識を適用する能力
- 論理的思考と問題解決能力:問題の構造を把握し、適切な解法を見つける能力
- 算数と代数学の知識:計算式を立てて解を求める能力
- 分野知識:問題が属する分野の基礎的な知識
2023年9月時点のGPT-4は、このような問題だけでなく、より難易度の高い問題もかなり解くことができるようです。実際、連鎖的な思考プロセスを促すようなプロンプティングを用いることで、GPT-4は次のような非常に難しい問題さえ解くことが可能です。
例題:異なる半径と有効温度を持つ2つの恒星からなる食変光星系があります。恒星1は半径R1、温度をT1とし、恒星2の半径をR2 = 0.5R1、温度をT2 = 2T1とします。小さな恒星が大きな恒星の背後に隠れた場合の、連星の放射等級の変化(Δmbol)を求めてください。この計算では、色による違いを無視し、放射等級のみを考慮します。
しかしながら、Alien Codingで報告されているように、この手法はわずかに難易度が高い他の問題には失敗します。以下のような物理学の問題や数論の問題が含まれます。
物理学の問題:円盤銀河を通る星の運動は、半径R、厚さL(L << d << R)の円盤の上に、距離d離れて静止状態から放出された点質量mとしてモデル化できます。この円盤は一様な密度を持ち、総質量Mは>>mです。この運動を記述してください。
数論の問題:2つ以上の素数からなる差が10の等差数列をすべて見つけなさい。
これらの問題は、Minervaがテストされたものよりも難易度が高く、優秀な高学年学部生や大学院生が取り組めば解ける可能性はありますが、時間を要する可能性があります。関連分野のバックグラウンドを持つ学生でも、解けない場合があるかもしれません。
LLMの真の能力は流動的であり、その限界を明確に把握することは容易ではありません。例えば、上記の数論の問題は、少し調整すればGPT-4でも解けそうな印象を受けます。しかしながら、優秀な数学の学生であれば解けるレベルでありながらも、より高度な論理構造を有する数論の問題は数多く存在します。これらの問題は、初歩的でありながら、非線形な論理構成を持ち、複数の論理ステップを有機的に繋ぎ合わせる必要があります。このような微妙な差異が示唆するように、LLMの能力の限界を理解するための示唆的な考察を行うことが重要です。その中でも特筆すべき点は、問題が非線形な論理構造を持ち、複数の論理ステップを有機的に繋ぎ合わせる必要がある場合、LLMは混乱を招きやすい傾向にあるということです。
Hyperonシステムにおける統合型AIを活用することで、より難易度の高い問題も含めてどのように解決できるでしょうか? 理解しやすく説明すると、LLMは常識的推論を得意とし、PLNは論理的推論に適しており、さらに英語を論理形式に変換する「セマンティックパーシング」イニシアチブは、LLMの常識的推論とPLNの推論を連携させる実用的な手段となります。関連分野の知識は、大量の英語テキストを論理形式に変換し、Atomspacesに取り込むことで獲得できます。これらの要素に加えて、これら問題を扱うために必要な唯一の要素は、PLNが特定の推論ステップを外部の計算機代数・算術システム(例:Julia Symbolicなど)への呼び出しで根拠づけるツールであるように思われます。つまり、PLNが代数方程式の簡略化、2つの式の同値性チェック、素因分解などのタスクを実行する必要がある場合、外部ツールを呼び出す必要があることを認識し、実行するということです。
このアプローチは、従来の人間の戦略とは異なり、人間が問題を解く際の正確な模倣を目指していない点が特徴です。Hyperonシステムは、学習済みのMeTTa手続きを用いて算術計算を実行したり、ロボットの指で計算機のボタンを押したりすることで、より人間らしい動作を実現することも可能です。しかし、Hyperonのアプローチは、人間が特定の問題を解く方法を正確に模倣することではなく、人間の心を構成する人工知能(AGI)に関連する重要な認知アーキテクチャを活用し、このアーキテクチャが持つすべての強みを活かして問題を解く方法を学習させることに重点を置いています。
これは明らかに人間と同じ解き方ではありません。Hyperonシステムには、学習済みのMeTTa手続きを通じて算術計算を行わせたり、ロボットの指を使って計算機のボタンを押させたり、より人間らしい方法で動作させることが可能です。しかし、Hyperonのアプローチは、人間が特定の問題を解く方法を忠実に模倣するのではなく、むしろ、人間の心の中のAGIに関連する重要な認知アーキテクチャを活用し、そのアーキテクチャが持つあらゆる強みを活かして問題解決を学習させることに重点を置いています。
LLMとHyperonによる自動定理証明
近年、大学院レベルの基礎科学演習を超えた段階にある自動数学定理証明へのAI活用が、新たな研究領域として注目されています。これは、初等的なパズルや演習レベルを超えた自動数学定理証明の実現を目指します。LLMを含む多種多様なAIアルゴリズムを用いて自動数学定理証明の性能向上に取り組む研究者の一人であるZar Goertzelは、この分野特有の課題を明らかにし、これらの課題こそがHyperonのアプローチを特に魅力的なものにしていると述べています。
自動定理証明におけるLLMの能力を適切に評価するためには、高度な設定や運用であっても、数学分野におけるLLMの限界を理解することが重要です。まず、LLMの比較的成功した応用例として、プログラム自動生成におけるAlien Codingプロジェクトを取り上げます。このプロジェクトでは、LLMを用いて数学的に意味のある整数列を出力するプログラムを自動生成し、その有効性を検証しています。
例えば、 (1, 1, 1, 1, 2, 3, 6, 11, 23, 47, 106, 235, 551, 1301, 3159, 7741, 19320, …) という数列は、いくつかの方法で生成できます。具体的には、n番目の項は、ラベルが付いていないノードがn個ある木の数などと表すことができます。このような短い数列とその意味の説明をLLMに与えて、将来の項も生成するプログラムを作成するように指示することができます。
このような文脈において、まず最初に行うべきことは、提示されたプログラムが任意のnに対して、標的となる数列を確実に生成できるかどうかを数学的に証明することです。しかし、現時点において、LLMはこれを信頼できる方法で実行できません。LLMが行うのは、プログラムが標的とする数列の最初のn項を正しく生成しているかどうかを検証することです。これはプログラムが数列のすべての要素に対して正しいことを証明するのとは異なり、はるかに困難なタスクです。そのため、LLMが生成または評価したプログラムは、「確率的に正しい」としか見なすことができません。しかし、この分野においては、確率的に正しいだけでは不十分であり、関与する確率が非常に高い(例:99.99%など) 確信に近いものでない限り、十分とはいえません。プログラミングや数学においては、一瞬のミスで1つの項を間違えてしまうと、実行エラーを引き起こしたり、証明全体を台無しにしてしまう可能性があります。
Hyperonは、この種のプログラム合成の改善に役立つ潜在的に有益な複数のツールを提供します。MeTTa言語は、証明の生成や探索のためのプログラミング言語や証明計算系の空間の進化的な探索を容易にするように設計されています。さらに、MeTTaは確率やその他の不確実性を評価する方法をネイティブに扱うようにも設計されています。証明論において、確率的な表現しかできない証明項を扱う場合、確率論理を用いた推論が望ましいでしょう。HyperonのPLNフレームワークは、まさにこのような機能に最適化されています。
一般的に、LLMがこの分野や他の分野で証明を導き出すことに成功する最大の障害は、文脈に適した形で複数のステップを連鎖させることが困難であることです。メモリもまた問題であり、証明の一部を念頭に置きながら別の部分に取り組みたい場合がありますが、LLMは現時点ではそのような機能を明確に持っていません。しかし、Hyperonのようなより広範なAIフレームワークがこれを容易にすることができます。興味深いことに、この2つの欠点は、従来の自動定理証明系にもそれぞれ異なる形で当てはまります。従来の自動定理証明系も、長い推論チェーンの戦略的構築(これが対話型定理証明が一般的な理由です)や、さまざまな種類のメモリを使用して推論ステップの選択を導くことに苦労しています。Hyperonのより認知的なアプローチは、これらの限界を克服する上でいくつかの可能性を秘めています。
Hyperonは、LLMが最も力を発揮する非形式証明の領域と、自動定理証明者が得意とする極めて詳細な低レベル証明の世界を橋渡しする可能性も秘めています。Hyperonは、数学者がアウトラインを描くような高レベルの証明概略を、自動化された記号推論のための形式論理に変換することができます。このようにして、LLMと自動定理証明者のそれぞれの強みを相乗的に活用することができるのです。
4.3.5 強化学習(Reinforcement Learning)
強化学習(RL)の基本的な考え方は、望ましい結果をもたらした行動を褒賞し(報酬を与え、選択される確率を高める)、望ましくない結果をもたらした行動を処罰する (ペナルティを与え、選択される確率を下げる)ことで、過去に成功した行動を基に新しい行動を探索し、より良い結果をもたらす行動を選択していく手法です。
この観点から考えると、ECANとPLNの組み合わせ(実行可能な手続きの論理バージョンに適用)は、暗黙的に強化学習を行っていると捉えることができます。例えば、これらの手法に確率的プログラム合成と、すでに試された手続きの集合から確率分布を明示的に誘導する手法を組み合わせることで、 より標準的な強化学習アルゴリズムに近似させることができます。
MeTTa上で古典的な強化学習アルゴリズムを実装し、Atomspace上で実行することは可能ですが、単純な報酬関数で表現できない複雑な現実世界への適用や、微妙で多次元的な内在的報酬が重要な状況への適用には課題が存在します。
ロボットの動作制御は、まさに古典的なRLが真価を発揮できる領域と言えそうです。高レベルの行動計画と低レベルの物理運動計画の連携は、確率プログラミングという形で実現できます。この確率プログラミングは、物理運動と行動計画を網羅する確率分布の導出を含みます。導出された確率分布は、運動制御を担う古典的RLアルゴリズムの探索と、より抽象的な「強化学習に似たECAN/PLNアプローチ」による計画の探索の両方を導く指針となります。
4.3.6 言語学習と使用法(Language Learning and Usage)
LLMは、自然言語対話や計算言語学分野の標準的なタスクにおいて飛躍的な進歩を遂げ、高い能力を示してきました。しかし、意味理解に関しては、特に形式的な知識が求められる文脈において深刻な課題を抱えています。また、LLMが生成する言語表現には、微妙さや芸術性、説得力が欠けています。
自然言語処理(NLP)研究者であるAndres Suarezは、大規模言語モデル(LLM)の登場が自然言語処理分野に大きな進歩をもたらした一方で、依然として克服すべき課題が残されていると指摘しています。彼は、LLMとシームレスな統合を可能とするHyperonアーキテクチャが、これらの課題を克服するための有望なアプローチであると論じています。
NLPにおける「理解」と「生成」の2つの主要な課題には、以下のようなものが挙げられます。
理解の課題
- 曖昧性:単一の文がその文脈に基づいて複数の解釈を持つことがあります。現在のモデルは、人間にとっては簡単な複雑な状況でも問題を抱えることがあります。例えば、「明日の会議の準備をしてください」という指示は、明日の午前中なのか午後なのか、必ずしも明確ではありません。
- 感情とトーン:言語に含まれる潜在的な感情、皮肉、ユーモアを正確かつ一貫して検出することは、現在のモデルには困難です。例えば、「素晴らしいプレゼンだったね!(内心はがっかりした)」のような皮肉を理解するのは難しいです。
- 動的な言語:言語は常に進化しており、適応できないモデルは時代遅れになるリスクがあります。新しいスラングや表現が次々と生まれており、モデルが追いつくのは容易ではありません。
- 矛盾:特に長い文章を作成したり、複数の情報を考慮する際に顕著になります。例えば、「彼はとても背が低いが、バスケットボール選手だ」という文は、一見矛盾しているように見えますが、文脈によっては矛盾していない可能性があります。従来のモデルは、このような文脈依存の矛盾を検出することが困難です。
生成の課題
- 誤った推論:表面的には論理的に見えるテキストを生成することは現在可能ですが、精査すると論理の飛躍が含まれることがあります。例えば、「雨が降っているので、今日はきっとビーチで泳げるだろう」というような、論理の飛躍を含む文章が生成されてしまうことがあります。
- 情報の取込漏れ:有限のコンテキストウィンドウとリアルタイム情報の外部データベースへのアクセスがないことが原因です。例えば、「ジョンは新しいレストランに行った。とてもおいしかったので、また行きたいと言っていた」という文章では、レストランの名前や場所が抜け落ちている可能性があります。
- 幻覚:生成されたコンテンツが事実上正確でない、いわゆる「ハルシネーション」と呼ばれる現象です。モデルが現実世界の情報を欠いているため、事実と異なる内容を生成してしまうことがあります。
Hyperonによる解決法
Hyperonは、これらの課題に対して次のような解決方法を提供します。
- LLMとの統合:LLMに備わっている言語的流暢さと、Hyperonの構造化された推論能力を相乗効果的に組み合わせることで、NLPに対するより包括的なアプローチが実現できます。
- 豊富な知識グラフ:Hyperonのアーキテクチャは、広範な文脈情報の格納を可能にし、曖昧さを減らし、全体的な整合性を向上させます。
- 根拠ある推論:現実世界のデータ、文脈、感覚入力に接続する能力が、言語モデルを理解と生成の両方を大幅に向上させることができます。
- 基盤となる推論:言語モデルを現実世界のデータ、文脈、または感覚入力と結びつける能力により、理解と生成の両方が大幅に改善されます。
- 論理エンジン:Hyperonの確率論理ネットワークは、曖昧な情報や不完全な情報を明示的に扱うためのフレームワークを提供し、より確固とした結論を導き出すことを可能にします。
- 継続学習:Hyperonは適応性を備えており、言語と共に進化し、新たなニュアンスを取り込むことができます。
- フィードバックメカニズム:このアーキテクチャには、NLP能力の継続的な学習と改善を促すフィードバックループが組み込まれています。
- ファクトチェック:Hyperonは生成された内容の正確性を保証するために、広範な知識ベースと照合して事実確認を行うことができます。
全体として、Hyperonアーキテクチャに代表されるように、深層学習技術とシンボリック構造推論の融合は、NLP分野に革命をもたらす可能性を秘めています。 この統合アプローチは、最新のLLMの能力と調和するだけでなく、これまでにない繊細なニュアンス、一貫性、そして文脈的関連性を持つ人間言語を理解し生成するNLPシステムの開発に向けて新たな道筋を示すものです。
Hyperonの潜在的な貢献を考える一つの方法は、NLPにおける統計的アプローチ(LLMがその代表例)と、より形式言語学的なアプローチの組み合わせという観点から捉えることです。ベン・ゲーツェルは、次のように述べています。構文、意味論、語用論の形式化は長い歴史を持っていますが、形式構造の簡潔なリストでは、自然言語の豊かさと繊細さを十分にカバーできないことも明らかになっています。LLMとAtomspaceを組み合わせると、極めて特殊な言語規則だけでなく、抽象化と一般化の階層構造を含む大規模な形式言語の知識体系を構築することができます。これにより、PLNによって生成された宣言的知識と、Hyperonの他の認知メカニズム (概念ブレンディング、言語パターン、構造など)との緊密な連携が可能になります。実現方法にはいくつかありますが、 有望な方法の一つは、構文と意味論の両方でグラフベースと論理ベースの構造を活用するワードグラマー形式論のバリエーションを活用することです。
このアプローチにより、理解と生成の両方のパイプラインを構築することが可能になります。理解パイプラインでは、LLMを用いて自然言語の文を論理的内容と形式的な構文的内容 (例:ワードグラマー)の組み合わせに変換します。生成パイプラインでは、形式的な構文的内容を部分的な仲介として用いて、論理的内容を構文内容に変換します。この統合されたアーキテクチャは、表面的な構文コーパス分析を超えた深い言語理解を実現し、より創造的で革新的な言語処理システムの開発につながる可能性を秘めています。
4.3.7 マルチモーダル知覚(Multimodal Perception)
マルチモーダル知覚(複数の感覚情報を統合する能力)は、ある意味で深層ニューラルネットワークによってかなりうまく処理されています。しかし、これらのネットワークが実際に認識している情報の本質をどの程度理解しているかは非常に限られており、これが統合認知システムにおける知覚皮質として利用する際に課題となっています。
この課題を解決するための自然なアプローチは、Atomspace内の「概念」や「関係性」と、ニューラルネットワークにおける重みと活性化パターンの形で表現される「概念」や「関係性」との間に、明示的なリンクを構築することです。この方法にはいくつかの手段が考えられますが、最も単純なアプローチは、特定のアトムをニューラルスペース内のネットワークにあるニューロンの組み合わせにマッピングする線形または非線形関数を学習させることです。例えば、Hyperonシステムが「猫」という単語でラベル付けされた画像を複数認識した場合、「猫」という単語を表すアトムから、視覚ニューラルスペース内のニューロンの組み合わせへのマッピングを学習することができます。
次のステップは、学習されたマッピングの大規模な集合を特徴づける確率分布の帰納的学習です。この分布に基づく確率的合成により、ラベル付きデータが少ない場合や、全くない場合でも、新しいマッピングを推論することが可能になります。
4.3.8 アクションラーニングと協調行動(Action Learning and Coordinated Action)
CogPrimeにおけるアクションラーニングは、基本的には他の学習方法と異なるものではありません。前述のように、RLに似た方法で実施することもできますし、特定の報酬関数に依存せず、既存の手続き知識の簡潔な一般化を追求するPLN推論や確率的プログラム合成によって、より純粋に実施することも可能です。
4.3.9 目標の明確化と目標システム管理 (Goal Refinement and Goal System Management)
Hyperonは、明確な目標志向を持つ多様な上位目標を持つシステム、目標概念を持たない自己組織化ネットワーク、または完全にではないが目標志向を持つ中間的なシステムなど、幅広い用途を想定して利用できるように設計されています。
明確な目標の追求は、PLN、RL型の手法 、確率的手続き学習、進化的手続き学習などによって自然に行われます。これらの手法は、異なる時間軸での複数の異なる目標や、ある程度互いに矛盾する目標さえも、自然な形でバランスを取ることができます。互いに矛盾する目標についての明示的な推論も、PLNの不確実性セマンティクスに自然にマッピングされる矛盾許容論理システムを使用することで、比較的容易に行うことができます。
Hyperonシステムの上位目標は、人間プログラマーによって設定することができます。しかし、もう一つの選択肢としては、概念形成ヒューリスティックとECANを介して生成することも可能です。この2つのアプローチを組み合わせることが、おそらく最適であると考えられます。上位目標からサブゴールを作成することは、概念形成とPLN推論を適用することで比較的容易に実現できます。
4.3.10 再帰的自己理解(Reflexive Self-Understanding)
Atomspaceは、再帰的自己理解のために明確に設計されています。すなわち、MeTTa、PLN、パターンマイニングなどの標準的なHyperonとCogPrimeの認知操作は、Atomspaceメタグラフを入力データ、出力先、中間結果の保存場所として扱うように設計されています。しかしながら、この基本設計だけで自動的に深いレベルでの再帰的自己理解を可能にするわけではありません。それは以下のことを意味しています。
- 学習アルゴリズムと推論アルゴリズムが十分に賢ければ、高度な再帰的自己理解を達成する上での障害はありません。
- 穏やかなレベルの再帰的自己理解を達成するために必要な学習アルゴリズムと推論アルゴリズムの知能は、必ずしも高くなくてもよい。(なぜなら、Atomspaceの設計は、概念的に単純な自己理解の問題が実際に単純なものになるよう、妨害要因を排除しているからです。)
このことは、次のような好循環が実現可能であることを示唆しています。「わずかな再帰的自己理解がシステムを少し賢くし、それによりさらに自己理解を深めることができるようになる」という具合です。この好循環により、システムが徐々に知能を高めていくことが期待できます。
4.3.11 他者の心のモデリングと理解
人間が他者の心を理解することは、(不確実な)他者の心の論理的モデリング、共感によるシンクロニー、そして他者の心の内部シミュレーションなど、複数の要素が複雑に絡み合っています。Hyperonはこれらすべての機能を実行できるはずです(感情については後述)。特にシミュレーションに関しては、いくつかの点で人間を大きく凌駕する可能性があります。
Hyperonインスタンスは、特定の他者の心のモデル化を目的とした他のHyperonインスタンスを生成し、訓練して調整することができます。すでにLLMを使用して、特定の人物が作成したテキストデータを微調整することで、完全に正確ではないものの、興味深い「テキストによる双子」を作成することが可能です。さらに、現在の深層ニューラルネットワーク技術を用いれば、人間の顔や声を不気味なほど正確に模倣することもできます。では、これらのネットワークを特定の人物の知識や性格を表すAtomspaceと密接に結びつけたらどうなるでしょうか? Twin Protocolと呼ばれるプロジェクトはこの方向に向かっており、実用的な機能を持つ商用製品の開発を目指しています。このアプローチは、Hyperonが特定の他者の行動を推論する際に非常に有用である可能性があります。
もちろん、次のステップは、これらの個々の心をモデル化したAtomspaceに基づいて、推論による汎用化を行うことです。このようにして、Hyperonシステムは、人間との感情的シンクロニシティにおいて、人間基準で比較した場合の欠点を十分に補うことができるかもしれません。 さらに、Hyperonインスタンス同士が相互にモデル化し合う場合、お互いの近似シミュレーションを構築する能力は、非常に役立つでしょう。
4.4 Hyperonとして存在するとはどういうことなのか?
次に、標準心モデルでは明確には重要な側面として取り上げられていないものの、さまざまな形で考慮されており、常識的に人間のような汎用知能の鍵となる側面について考察します。これらの側面は、汎用知能の経験的および主観的な側面、つまり「Hyperonとして存在するとはどういうことなのか?」という点に少し重きを置いています。
4.4.1 世界モデリング(World Modeling)
AGIシステムの「世界モデル」は、一部のロボット制御システムのように必ずしも独立したコンポーネントである必要はありません。むしろ、システム内のさまざまな知識ストアに分散して暗黙的に存在することができます。
しかし、暗黙的な世界モデルは依然として幅広くばらつきがあり、洗練度や有用性に差が生じることがあります。例えば、特殊なケースを除いて、LLMの世界モデルは著しく不十分であることは明らかです。その根本的原因は、知識が膨大な特殊事例で構成され、過度に特化していることにあると考えられます。LLMの知識にはいくつかの暗黙的な抽象化が存在しますが、これらの抽象化を適応的に展開する能力は、適切な特殊事例を見つけ出し変形させる能力と比較すると、比較的限定的です。
Hyperonシステムの世界モデルは、部分的にPLNや概念生成などの手法を用いて、特定の事例から学習された抽象化によって構成されます。明示的な因果関係の学習は、この過程において重要な役割を果たします。RL型の手法もまた、因果関係の学習において重要な役割を果たすことができますが、この場合の因果関係はより具体的な性質のものであることが多く、推論による抽象化の対象にもなります。
計算システムは、生物の脳にはない世界モデルの構築能力を備えています。例えば、Hyperonインスタンスは、物理エンジンを直接実行することで物理システムをモデル化したり、ネットワークシミュレーションを直接実行することで、自身のインフラの一部であるコンピュータネットワークをモデル化することができます。これらのシミュレーションのパラメータを抽象的な理解に基づいて調整したり、様々な条件下でシミュレーションを実行して、潜在的に関連する新しい抽象化を学習することもできます。これは、Hyperonのコアとなる認知アーキテクチャが人間の認知科学に大きく影響を受けている一方で、本質的には(OpenCog Tachyonが登場するまでは)デジタル計算システムであり、そのデジタル基盤がもたらすあらゆる利点を最大限に活用できるよう設計されていることを示しています。
4.4.2 感情(Emotion)
Joscha Bachのヒト型知能モデルであるMicroPsi理論(図18と19参照)は、Dietrich Dornerの初期のPsi理論を基に、人間の一般的な感情を行動、知覚、記憶に関わる認知サブシステムのパラメータとして扱っています。Cai Zhenhuaによる2011年の博士論文では、このモデルをOpenCog Classicに実装し、3Dシミュレーション世界を探索する単純な仮想エージェントの文脈で探求されました。また、このモデルをSchererの『感情のコンポーネントプロセスモデル』と結びつけ、ヒューマノイドロボットやアバター向けの感情モデルの実装指針としても活用しています。
- DornerのPSI理論に基づく計算感情モデルのダイナミクス:Dynamics of a computational affective model inspired by Do¨rner’s PSI theory
- ヒューマノイドロボットとアバターにおける感情表現、生理機能模倣、意図的行動、ジェスチャー(表現):Emotion, Physiology, Motivated Action and Gesture/Expression for Humanoid Robots and Avatars
この開発ラインは、幾分稚拙で単純化されすぎている部分もありますが、以下の点において有効であると考えられます。
- 感情と認知システムの他の側面との繋がりを適切に説明することができる
- AGIシステムに、標準的な人間の感情の粗い類似体を提供する方法を提供する(ただし、構築しているシステムの種類によっては、必ずしも望ましいとは限りません)
- AGIシステムに、標準的な人間の感情の粗い類似体を提供する方法を提供することができる(ただし、構築しているシステムの種類によっては、必ずしも望ましいとは限らない)
- 標準的な人間の感情とは大きく異なる可能性のあるAGIの感情について、体系的に考える方法を提供することができる
4.4.3 創造性(Creativity)
複雑な認知システムにおける創造性は、非常に多様な源泉から生まれます。ゲーツェルの著書『複雑系から創造性へ:From Complexity to Creativity』では、以下のような基盤となるダイナミクスの観点から創造性の根源を分析しています。
- 過去の認識に基づく個別要素の変化(進化論的学習用語でいう”突然変異“)
- 過去の認識の要素の組み合わせ(”交差“)
- 相互作用する要素同士が複雑に絡み合って新たな秩序や構造を自律的に生み出すこと(”自己組織化による出現“)
これらの要素をそれぞれ効果的に実装することは、実際には非常に繊細な作業を伴います。現在の生成系AIモデルであるLLMなどは、訓練データで観察された表面的なパターンを変化させ、組み合わせることで、限られた創造性を発揮しています。これらのモデルの限界は、突然変異や組み合わせの操作の限界によるものではなく、システム内に容易に操作可能な抽象表現が欠けていることに起因しているようです。より根本的に創造的な方法で変化させ、組み合わせるには、より抽象的な表現が必要となります。これは、ダグラス・ホフスタッターがより創造的で抽象に精通した「ノブ作成」と呼ぶものであり、表面的なレベルで定義された調整可能な特徴の「ノブ回し」とは異なります。
CogPrimeにおける創造性は、芸術、文学、数学、科学、社会分析、自己分析といった文脈において、進化学習、不確実推論、確率的合成、自己生成的な「Cogistry」書き換え規則ネットワークなど、複数の手法を組み合わせたものとして定義されます。創造性は、Psi理論で論じられた知覚、行動、記憶のパラメータにおける感情の基盤に基づき、本質的に感情に駆動されます。しかし、何よりも重要なのは、効果的な創造性とは、新しい創造物のための原材料として用いられる多様な知識内容を、適切に抽象化された表現によって強く導かれるものであるということです。
4.4.4 意識(Consciousness)
「意識」という用語は非常に曖昧で、以下のような様々な意味を持つことができます。
- 明確な世界認識と自己認識:これは、私たちが覚醒している時に持つ意識です。深い睡眠や麻酔下では、この意識は失われます。
- 再帰的自己理解:人間の方が犬より多く持ち、犬はミミズより多く持ち、大人の方が赤ちゃんより多く持つなど、程度に差があります。
- クオリア(Qualia):意識しているという生々しい主観的感覚。おそらくあらゆる素粒子にも見られる、環境に対する何らかの気付きや反応。
デジタルコンピュータシステムが、人間と同じ意味で意識を持つことができるのかという議論が活発化しています。しかし、人間でさえ意識体験と肉体的・生物学的活動との関連性が十分に解明されていない現状では、科学的に結論を出すことは困難です。ベン・ゲーツェルは、ブレイン・ブレイン(脳-脳)やブレイン・コンピュータ(脳-コンピュータ)インターフェースを活用することで、これらの問題を新たな視点から探求することを提案しています。
- 簡単な3つのステップ:脳-コンピュータインターフェースと二人称科学で意識の難問を解決:Easy as 1-2-3:Obsoleting the Hard Problem of Consciousness via Brain-Computer Interfacing and Second-Person Science
ゲーツェルの論文 『人間型意識の特性:統合的アプローチ:Characterizing Human-Like Consciousness: An Integrative Approach』では、意識に関する問題や、人間の脳とAGIシステムにおける構造やダイナミクスについて探求しています。しかし、現実的な観点から見ると、この分野は未知の領域が多く、AGIシステムの構築という地道な作業においては、意識体験そのものについての疑問は脇に置かれ、代わりに「意識の神経的および認知的相関関係」という観点で研究が進められているのが現状です。
これらの観点から見ると、 Hyperonシステムにおける「再帰的な自己認識的意識(覚醒状態の意識)」の主要な相関関係は「注意焦点」です。注意焦点の内容とダイナミクスは、一般的な解釈におけるHyperonシステムの「意識状態」を決定する主要な要素であると考えられます。
4.5 Hyperonを代替認知アーキテクチャの基盤として
Hyperonを開発するチームは、主に前述のCogPrime認知アーキテクチャに焦点を当てたAGI研究開発を進めていますが、Hyperonは代替的なAGIパラダイムやアーキテクチャの実験にも有効に活用できるよう設計されています。
もちろん、あらゆる種類のAGIアプローチに同じ基盤が有効であるとは限りません。しかし、複数のAGIアプローチを同じ基盤とツールセット上で追求できる限り、その結果や強み、弱みを比較しやすく、特定のAGIアプローチにとどまらず、広範な用途で利用可能なモジュール、 アルゴリズム、または表現を組み合わせることが容易になるかもしれません。この観点から、以下のような議論がされています。
- NARSコミュニティとの議論:NARSコミュニティのメンバーとの間では、NARS推論システムと認知アーキテクチャのバージョンを実装するための基盤として、MeTTaとHyperonの潜在的な利点について議論が行われています。
- 生物学的ニューラルネットワークの実装:Hyperonを使用して、非常に生物学的にリアルなニューラルネットワークを実装する可能性について議論されています。これには、非線形ダイナミックニューロン(Hodgkin-Huxley方程式やIzhikevichのカオスニューロンに基づく)や、Alex Ororbiaの予測符号化モデルに基づくバックプロパゲーションの代替手法、またはYi ZengのBrainCogアーキテクチャなどが検討されています。
4.5.1 SISTERのインフラとしてのHyperon
Hyperonを利用して代替的な認知アーキテクチャを実装し探求するもう一つの潜在的な例として、Rejuve NetworkのCTOであるDeborah Duongは以下のように述べています。
私が長い間取り組んでいるSISTER(Symbolic Interactionist Simulation of Trade and Emergent Roles)フレームワークは、LLMをシンボリック推論システムと統合するための有望なアプローチを提供するニューロシンボリックアーキテクチャです。
SISTERの主な利点は、下位レベルのダイナミクスからシンボルと意味の社会的出現をモデル化できる点にあります。これは、概念が人間同士の相互作用と集団的意味形成を通じて生じるプロセスに似ています。そのため、SISTERは明示的なシンボリックな定式化の前に暗黙の表現を生成することができます。SISTERの自律エージェントは自己組織化し、共有シグナリングシステムと概念空間を構築し、新しい抽象化が出現するにつれてそれを取り込んでいきます。
SISTERは、通信のコンパクト化とリソース制約への適応を実現するとともに、受信者が異なる文脈を持っていても理解できるようにし、新規情報の表現と合成を可能にする選択圧力を生み出します。特筆すべきは、コンパクトで文脈に依存せず、組み合わせ可能というSISTERの特性が、数学とシンボル処理の創出を促進する点です。このことから、SISTERをニューロシンボリック知識抽出に用いることは、符号のコンパクト性、 文脈非依存性、合成可能性の選択を行わずに内部ニューラル状態からシンボルを抽出する方法よりも優れていると結論付けられます。
これらの暗黙的表現が外部化されると、Hyperonのような確率論的論理ネットワークは、それらを人間が理解できる明示的な論理構造へと変換することができます。これにより、新しい概念の帰納、論理的推論による演繹、そして新しい仮説のアブダクションによる知識の拡張が可能になります。要するに、SISTERは出現するシンボルグラウンディングを通じて、Hyperonのニューロシンボリックな能力をブートストラップするための道筋を提供し、Hyperonの強みを補完します。
4.6 スーパーインテリジェンスの基盤としてのHyperon
人間のような認知アーキテクチャを一定程度抽象化して模倣することは、生物学的構造やダイナミクスのシミュレーションを必要とせずに、人間レベルのAGIを実現するための有効な手段であると考えられます。しかし、ここまで論じてきたように、ある程度人間に近い認知アーキテクチャを持つHyperonの具体的な問題の対処方法は、人間が問題に取り組む方法とは大きく異なることが明らかになっています。人間は脳をJulia Symbolicsに直接接続したり、全ての知識ベースに対して体系的にパターンマイニングしたり、学習した手順を単純な形式変換を用いて宣言的表現に変換したりすることはできません。Hyperonはこれらのことができ、これらを自己理解や世界理解の基盤を強化する方法で行う限り、それを実行しない理由はありません。
人間のような認知アーキテクチャをある程度の抽象レベルで模倣することは、 たとえその基盤となる要素が生物学的な構造やダイナミクスをリアルにシミュレーションしなくても、人間レベルのAGIの創出に向けた有効なアプローチであると私たちは考えています。しかし、ここまで論じてきたように、ある程度人間に近い認知アーキテクチャを持つHyperonの具体的な問題の対処方法は、人間が問題に取り組む方法とは大きく異なります。人間は脳をJulia Symbolicsに直接接続したり、自身の知識ベースを体系的にパターンマイニングしたり、学習した手順を単純な形式変換を使って宣言的表現にマッピングすることはできませんが、Hyperonはこれらのことが可能です。そして、Hyperonがこれらの機能を自己理解や世界理解の強化に貢献する方法で行う限り、それを実行しない理由はありません。
Hyperonが人間レベルの汎用知能から、根本的に人間を超える超知能へと移行する鍵となるのは、まさにこれらの人間とは異なる側面であると考えられます。私たちは、もしHyperonに人間レベルの汎用知能を獲得させることに成功すれば、ほぼ必然的に超人的な知能に移行すると確信しています。Hyperonは、自身の知識ベース全体を内省し分析することができ、その理解に基づいてすべての知識を明示的に修正し、あらゆる認知手続きを書き換えたり再設計したりすることができます。これは、人間の脳の構造では到底到達できないレベルの自己理解と認知的洗練であり、率直に言って、概念的にすら把握するのが困難なさまざまな形態の超知能へと明らかに道筋を拓くものです。
図20に描かれているGOLEMメタアーキテクチャは、自身のソースコードを再考し修正できるAGIの構造とダイナミクスを理解するための非常に簡略化された方法の一つです。このアプローチでは、「基本動作プログラム」と呼ばれる世界で様々な行動を実行するAGIシステムと、上位の最適化システム(メタレベル最適化システム)が存在します。メタレベル最適化システムは、高レベルの目標に基づいて基本AGIシステムの可能なアーキテクチャ空間を探索し、基本システムのコードを修正します。このプロセスでは、基本システムのコードを更新する前に体系的なテストを行い、問題が生じた場合はロールバックすることも可能です。このようなアプローチは、すべての自己修正を通じて特定の初期目標を維持しようとする硬直的な方法を採用することもできますし、より興味深いのは、経験を通じて上位レベルの目標を変更できるものの、通常はベースとなるAGIシステムの変化に比べてかなり遅いペースでしか目標が変更されない、よりオープンエンドな方法で利用することもできるということです。この種のシステムにおける、全体的な認知進化に関連した目標の進化のダイナミクスは、現時点ではまだ十分に理解されていません。
ベン・ゲーツェルはこう述べています。一部の理論家は、「Hyperonを初期基盤とし、目標更新能力を備えたGOLEM」のような強力な自己修正システムは、誇大妄想、快楽主義、完全な自己中心性などの病的な目標体系に収束する可能性が高いと主張しています。しかし、このような主張を裏付ける合理的な根拠は乏しく、私自身の直感は全く異なります。このようなシステムが何らかのアトラクターに収束する傾向があるとしても、それはむしろ慈悲深く利他的な性質を持つものになると推測します。しかし、現時点における科学は、この分野においてわずかな示唆を与えるに過ぎません。したがって、私たちの考え方は厳密な結果よりも直感によって導かれる必要があります。
『汎用知能の一般理論(GTGI)』 は、”Hyperon 1.0″ のようなシステムと成熟したGOLEMシステムの中間にあるシステムのスペクトルを考えるための合理的なツールを提供します。GTGIは、ガロア接続の観点から認知アルゴリズムを定式化し、これらを「組合せ操作ベースの関数最適化 (Combinatory-Operation-Based Function Optimization:COFO)」プロセスの特殊ケースとして表現しています(図21参照)。この種のプロセスは、無限に近い計算資源があれば非常に正確に実行できますが、現時点で現実的な計算資源しかない場合は、より多かれ少なかれヒューリスティックな方法で実行されます。ここで、人間のような知能は、歴史的に人間にとって関連性のある環境で特に有用なヒューリスティックなネットワークに対応します。膨大な計算リソースはあるものの、常軌を逸脱した程ではない場合のCOFOの挙動を調べることは興味深いものであり、これは人間中心の汎用人工知能(HCAGI)と、根本的に人間を超える超知能(ASI)との間の、連続的な進化の過程についての洞察を与えてくれる可能性があります。これは、論文『リソース豊富な心のための強健な認知戦略:Robust Cognitive Strategies for Resource-Rich Minds』で論じられている考え方に関連しており、そこでは以下のような認知戦略が探求されています。
そのような高度な認知戦略は、物理的に実現可能なシンギュラリティ以降の超知能にとっては十分可能かもしれませんが、基本的なHCAGIの認知ヒューリスティックの範疇を超えたものになるでしょう。
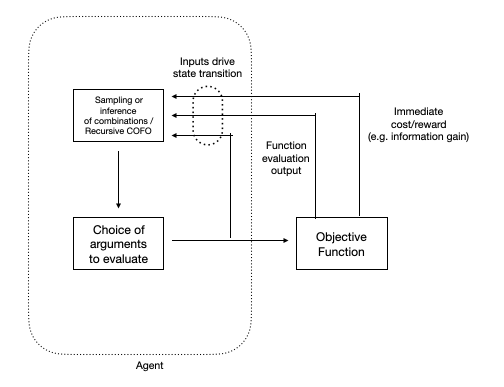
もちろん、このような状況を実現するには多くのステップが必要です。現在のプレアルファ版のHyperonシステムには、生後1歳児に見られるような汎用知能の多くの側面が欠けていることは周知の事実です。しかし、私たちが取り組んでいるアーキテクチャの潜在能力をできる限り明確に理解しておくことも重要です。
4.6.1 Hyperonと普遍的人工知能(ユニバーサル・インテリジェンス:ASI)の方法論
スーパーインテリジェンスは、多くの点で人間の理論や直観を超越する可能性が高いでしょう。しかし、我々の持つ数学理論の中には、日常の直観を超えたスーパーインテリジェンスの側面を包含している可能性もあります。AGIの数学的理論には、マーカス・ハッターのAIXIやユルゲン・シュミットフーバーによるゲーデルマシンなど、現在の計算資源では実現不可能なアプローチがいくつか存在します。しかし、これらのアプローチは、根本的に人間を超越した知性が思考する仕組みの一端を捉えている可能性があります。Alexey Potapovは、Hyperonとこれらの数学的な汎用知能アプローチの関係について次のようにコメントしています。
Hyperonは、プラットフォームとして普遍的帰納法やAIXIの実装を含んでおらず、その基本設計原則においてさえ情報理論的基準を考慮していません。にもかかわらず、その開発はAGIに関する情報理論的なアプローチによってもたらされました。
Hyperonはパターンマッチングを基本動作とし、すべてのアルゴリズムをパターン形式で表現します。これにより、アルゴリズムの規則性を扱いやすくなり、それらは宣言的な合成可能形式で表現されます。Hyperonの特別なモジュールの一つにパターンマイナーがあり、これは情報理論的な驚きの基準を使用します。そのため、Hyperonは普遍的帰納法に基づくAGIシステムの実装を強制はしませんが、アルゴリズム情報理論の要素を活用しやすい設計になっています。
チューリング完全な確率的プログラミング言語(PPL)は、普遍的帰納法とその関連理論の実践的な実装とみなすことができます。実際、全てのプログラムを生成する確率的プログラムを書き、それを観測データに基づいて条件付けることで、PPLインタプリタに実装された特定のサンプリングや推論アルゴリズムによって普遍的帰納法を近似できます。PPLにおける効率的な推論は、効率的な普遍帰納法に対応します。しかし、AGIの設定では、知識ベースの宣言的推論、メタヒューリスティック探索(例:遺伝的プログラミング)などの手法がなければ、これを達成することは難しいかもしれません。現在のところ、どのプログラミング言語やフレームワークも、このような普遍的な確率モデルに対する推論制御を実装するためのツールを提供していませんが、これはHyperonの主要なユースケースの一つとなっています。
普遍的人工知能(ASI)の領域では、論理に基づくモデルが数多く存在します。ゲーデルマシンはその代表的な例です。最近のAIXIの派生型の中には、推論に適した宣言的な形で「自然法則」の抽出することを前提とするものもあります。自己書き換え可能な公理系を持つゲーデルマシンをHyperonで実装することは、他のどのフレームワークよりも簡単かもしれません。
このように、Hyperonは普遍的帰納法やAIXIに基づいて構築されたものではありません。しかし、基本的なモデルを大きく超えたそれらの拡張を実験するために有用であり、さらにはそれらに基づいた完全なソリューションを開発することも可能と考えられます。
ベン・ゲーツェルは次のように述べています。2008年に初めてNil Geisweillerに出会った時のことを覚えています。彼はその後、Hyperonにおける主要なAI開発者の一人となり、PLNやメタグラフパターンマイニングなど様々な分野で活躍しました。当時、私はAGI設計に関する自分の考えを彼に説明しました。すると、彼は「私のアイデアは本質的に近似的なゲーデルマシンに思える」と答えました。ゲーデルマシンとは、ユルゲン・シュミットフーバーが提唱した理論的な理想化されたAGIシステムで、大まかに言えば、形式的に証明できる最も効果的な行動と自己修正を行うシステムです。私は彼の意見に同意しましたが、それは私の複雑な認知アーキテクチャに関する思考に対するやや控えめな称賛のように感じられました。ゲーデルマシンにはもっと単純な近似も存在しますが、人間にとって重要なタスクに対してうまく機能し、現実的なリソースで動作する近似を見つけることは、認知アーキテクチャ設計全体の根本的な問題を別の言い回しで表現したに過ぎません。
数年後、私は現在「マインド・ワールド対応原理」と名付けた概念を提唱しました。これは、特定の環境における目標セットに対して、ある程度の汎用知能を持つシステムを構築するには、そのシステムの構造の中に、目標に対する環境のパターンと密接に同型なパターンセットを組み込むべきであるという概念です。例えば、環境が階層構造を持ち、システムの目標が階層の異なるレベルに属するサブゴールに分解される傾向がある場合、この状況を効率的に処理するためには、認知システムのメンタルアーキテクチャも階層的なパターンを持つ必要があります。
GOLEMのような汎用知能を持つメタシステムは、現在の環境や目標のパターンを識別し、それらのパターンをより適切に反映するように動作プログラムを修正することができます。一方、人間の心や文化のような自己修正能力が限定的なシステムでも、適応や発展を遂げる過程で、ある程度同様のプロセスが行われています。
Geisweillerは、自身のHyperonにおけるAGI研究において、ゲーデルマシンに関連した視点を持ち続けています。ゲーデルマシンは、理想的ではありながらも実現可能な自己書き換えシステムで、システムの改善が形式的に証明された場合にのみ書き換えを行います。問題は、そのような証明を生成することにあります。目標定理が必要とする長い推論の連鎖を作成するのは極めて困難です。
推論制御のメタ学習は、この問題を解決する糸口となる可能性を秘めています。過去の成功した推論と失敗した推論の履歴を記録し、マイニング することで、推論制御のルールを発見し、検索を過去に成功したと判断された推論に偏らせることで、将来の推論を高速化することができます。しかし、成功と失敗を区別する学習には、少なくとも一度は成功を経験する必要があるという課題があります。自己書き換えの改善に関する証明を見つけるという文脈では、これが難しいかもしれません。
それでも、いくつかの解決策が考えられます。第一に、比較的単純な書き換えであれば、パラメータ調整などの手法を用いることで、ある程度の時間内に証明が見つかる可能性があります。そうすれば、次第に難易度を上げていく証明のコーパスを構築することも考えられます。第二に、より重要なポイントとして、自己書き換えの改善に関する推論制御の知識は、自己書き換えの改善とは全く関係ない問題を解決することで学習できるほど汎用性が高い可能性があります。これがどの程度当てはまるかは検証が必要ですが、少しでも可能性があるならば、システムが世界の問題を解決することで自分自身の問題も解決することを学び、自己改善の好循環を始める効果的な方法となるでしょう。
4.6.2 複雑性、自己組織化、そしてスーパーインテリジェンスへの道のりの創発
Hyperonの初期バージョンは細心の注意を払って設計されており、ここまで取り上げた基盤となる設計原理やアイデアの多くを探求してきました。しかし、もしプロジェクトが成功し、Hyperonのバージョンが人間の知能レベルを超えるようになれば、それらは急速に自己設計し、自己修正するシステムへと進化します。 これは、初期段階においては知識や認知的ヒューリスティックのみが複雑に進化し、コアアルゴリズムやメタ表現は固定されているのに対し、Hyperonはこれらの制約から解放され、より高度な複雑系科学の領域へと踏み込むことを意味します。
これは、Hyperonの自己発展の後期段階を理解する上で、普遍的人工知能(AGI)理論の概念だけでなく、カオスと複雑系科学からの概念も重要になってくることを示唆しています。
Matt Ikleが指摘するように、汎用人工知能(AGI)研究には、多くの根本的かつ定義に関する大きな疑問が存在します。そもそも、知性、意識、生命とは何なのでしょうか?最初の単細胞生物はどのように形成されたのでしょうか?どのようにして「無から有」を生み出すことができるのでしょうか?シリコンの電気的特性を変更し、電気と大量のプログラミングを加えることで、最終的にAGIを作り出すことができるのでしょうか?
これらの疑問に対する部分的な答えは、非線形現象、自己相似性、フラクタル、複雑系力学、自己組織化マップ、 自己修正システム、相転移、創発現象など、「カオス理論」関連の分野の広範な領域に潜んでいる可能性があります。
最新の神経科学研究では、このような非線形現象がAGIの創出に重要であることが明らかになりつつあります。最近行われた1週間の神経科学実験では、人間の脳波(EEG)のダイナミクスは「断続平衡」のパターンとして説明されました。このパターンは、ネットワークが特定の行動に対応する安定状態を保持する期間と、予測が難しく、カオス的な特性を示し、行動の変化に伴う一時的な突発的活動によって中断されることを意味します。脳の状態の統計解析では、単純で安定した構成要素から複雑性が生じる、臨界ダイナミクスに特徴的なべき乗則が見られることが分かりました。これらの結果は、現実世界の行動を支える複雑で柔軟な脳のダイナミクスが、単純なダイナミクスを持つ個々の安定したネットワークが混合して生じる創発的な特性であることを示唆しています。
興味深いことに、このような断続平衡のパターンは、Hyperonの基盤となる複雑系ダイナミクス理論の「ストレンジアトラクター」と驚くほど似ています。これらのアトラクターは、最初は人間が提供した認知アルゴリズムの枠組みの中でシステムが獲得した知識に関連付けられますが、その後はシステム自身の認知アルゴリズムや低レベルの実装コードの形成と修正にも関連付けられるようになります。
複雑系理論は、前述のオープンエンドインテリジェンス(OEI)理論の主要な着想源の一つでもあります。OEI理論は、汎用知能を「個体化」と「自己超越」のダイナミクスを組み合わせた自己組織化プロセスとして捉えます。この理論では、ユニバーサル・インテリジェンス(普遍的知能)への到達は、汎用知能が自らの限界を超え、自己超越しようとする試みであり、個体化を脅かすまたは弱体化させる条件を克服する試みであると見なされます。OEIがさまざまな方法でユニバーサル・インテリジェンスへと接近する過程で何が起こるかを理解することは重要ですが、それは進化し重なり合う知能が織りなす複雑な自己組織化の創発的ダイナミクスの一側面に過ぎません。この視点において、Hyperonのようなオープンエンドインテリジェンスシステムの成功は、システムが一定期間存続し、その間に人間の創造者や初期バージョンでは想像し得ないほど広範で豊かなシステムへと変容することにかかっています。
5. Hyperonの開発パス
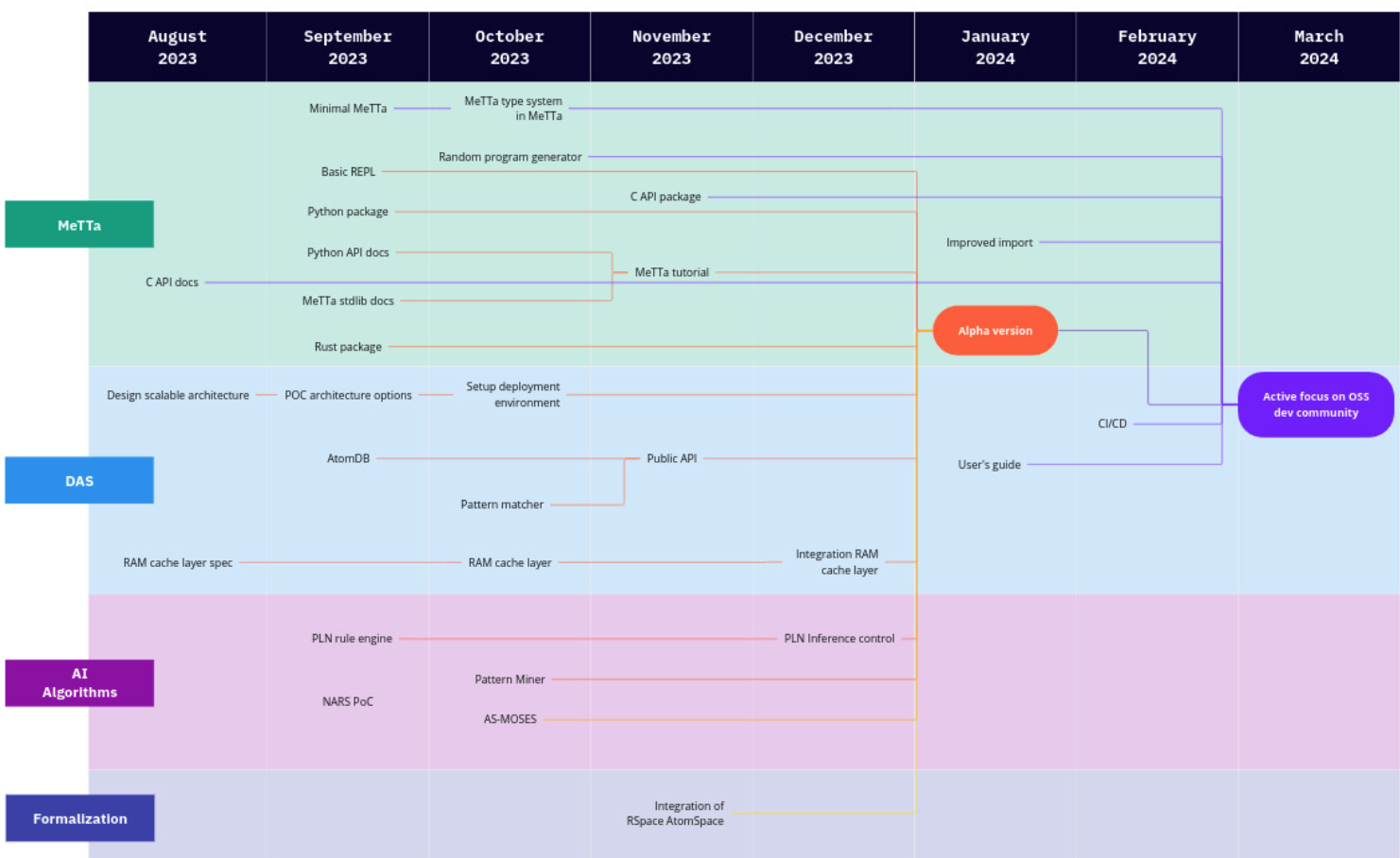
(具体的なアプリケーション、デモ、商用化努力は含まれません)
Hyperon構築の概要を説明しましたが、それでは組織的にどのように構築を進めるのでしょうか?もちろん、「とにかくやる」ことが肝心です。現在、Hyperonの開発には専任チームが取り組んでおり、今後も継続し、加速化していく予定です。今後予定している開発ロードマップの概要は図22に示されていますが、これは構想している戦略の全てではありません。堅牢なオープンソースコミュニティを構築し、積極的な商業化活動を推進することで、さらに多くの人材と知見を取り入れることができれば、より効果的であると考えています。
5.1 Hyperon開発コミュニティの拡大
ベン・ゲーツェルは、OpenCogプロジェクトにおける開発者との関係の歴史を次のように振り返っています。「OpenCog」という名前は、単にオープンソースの認知アーキテクチャを作成するだけでなく (そのようなものは他にもたくさんあります)、AGIを人間レベル以上に高めるという野心的な目標や、さまざまな実用的なアプリケーションに向けて、大規模なコミュニティによるオープンな共同作業プロセスを作り出すことを意図していました。しかし、少なくとも現時点では、「大規模なコミュニティ」という部分については失敗に終わっています。興味深いエンジニアリングと研究を行い、OpenCogをいくつかの実用アプリケーションのバックエンドで使用し、オープンソースの世界から数名の優れた開発者を獲得しましたが、本当に活発で大きなオープンソースコミュニティを形成させるまでには至っていません。
これにはいくつかの理由があったと思います。OpenCog Classicは実用的な意味で使いやすいとは言えず、初心者の開発者が簡単に触れられる魅力的なデモも用意していませんでした。もちろん、AGIの追求はつい最近まで人気のある分野ではありませんでした。今は全く新しい時代であり、AGIはより多くの開発者にとって興味深いものとなっています。したがって、開発コミュニティの分野でもAGIの研究開発の分野でも、OpenCog Classicで失敗したことをHyperonで成し遂げる大きなチャンスがあると思います。しかし、これを実現するためには、現在の状況でも使いやすさに十分注意を払い、開発者が触れて楽しめるような簡単に実演可能で興味を引く中間製品を用意する必要があります。どちらも、特別な専門家チームによるAGI研究開発のために、単にHyperonを使用するのとは少し異なる努力が必要です。
これまでHyperonの開発は、SingularityNETとTrueAGIに携わる少数の開発者グループによって進められてきました。コードはオープンソース化されていますが、開発作業自体は比較的閉鎖的な状況で行われてきたと言えます。
しかし、コードだけでなく開発コミュニティの両方に関して、状況をオープンにする明確な計画があります。現在の開発ロードマップでは、2024年第1四半期末頃に、Hyperonシステムのアルファ版をリリースすることを目指しています。このアルファ版は、主要コンポーネントであるMeTTaインタプリタと分散アトムスペースを中心に構成されています。このリリースに合わせて、活発なHyperon開発者コミュニティを構築するための本格的な普及活動を開始する予定です。現在のAGIに対する熱狂ぶりを考えると、これはOpenCogの歴史的な取り組みよりも、比較的容易な試みになると期待しています。ただし、最近のAGIに対する熱狂の大部分が、より異質な認知アーキテクチャではなく、特にLLMに向けられていることを考えると、必ずしも簡単ではないことも予想されます。
5.2 初期のデモンストレーションと応用の可能性
アルファ版リリースに併せて、初期のHyperonコードベースを使用した実用的なデモをいくつか準備中です。現在検討中のアイデアとしては、以下のようなものが挙げられます。
- Minecraftプレイヤーアシスタント:Hyperonとプログラム合成技術を活用して、Minecraftをプレイするアシスタントを開発します。このアシスタントは、プレイヤーの指示に従ってゲーム内の操作を実行したり、自動的に戦略的な行動を取ったりすることができるようになります。
- ヒューマノイドロボット対話システム:現在ヒューマノイドロボットGrace、Sophia、Desdemonaの対話システム制御に使用している大規模言語モデルに、書き換え可能なアクティブメモリを追加します。このアクティブメモリによって、ロボットは過去の会話内容や現在の状況をより柔軟に記憶し、より自然で人間らしい対話が可能になります。
- 生成型AIのシンボリック制御:Hyperonベースのフレームワークを開発し、生成型AIをシンボリックに制御します。特に画像生成において、複数の安定拡散モデルを柔軟に組み合わせ、従来の手法では実現できなかったような新構造の生成を可能にします。
- Rejuveプロジェクトにおける生物学的年齢推定:現在、個人のさまざまな属性に基づいて生物学的年齢を推定するベイジアンネットワークの代わりに、RejuveプロジェクトでPLNに置き換えます。PLNは、より高度な推論能力と柔軟性を備えており、より正確な年齢推定が可能になると期待されます。
これらの比較的単純なアプリケーションに加え、長寿研究における知識発見のためにPLNを活用する実験も進めています。Rejuve Biotechプロジェクトは、SingularityNETが推進するイニシアチブの一つであり、通常のハエよりも5~8倍長寿なハエの研究に焦点を当てています。これらのハエのDNAを分析し、すでに彼らの長寿のメカニズムをある程度解明しています。現在、転移学習と呼ばれる手法を用いて、これらの長寿要因のうち、どれが人間に適用できるかを判断することに取り組んでいます。これはPLNにとって非常に興味深いユースケースです。一般的にゲノミクス分野で用いられる大量のデータを扱うディープラーニングや機械学習アルゴリズムとは異なり、PLNは限られたデータ量でも有効な結果をもたらす可能性を秘めており、この分野における革新的な活用法として期待されています。
中期的な展望(今後1 ~ 2年程度)として、以下の2つの主要な焦点領域があります。
- Neural-Symbolic統合による大規模言語モデルの強化:Neural-Symbolic統合によって、より高度な知能を持つチャットシステムを構築します。前述のように、HyperonとLLMを連携させることで、LLMの弱点である複雑な多段階推論や根本的な創造性を克服できると考えています。
- ビデオゲーム内のバーチャルエージェントの制御:ビデオゲームの世界で複数の仮想エージェントを制御することにより、自己修正型コードベースの優れた実験場を構築します。具体的には、Sophiaverseメタバースにおける「Neoteric」と呼ばれる「人工生命種(Alife species)」を、Hyperonで制御することが考えられます。
5.3 商用化
Hyperonは、分散型インフラツールと統合されたオープンソースプロジェクトであり、世界中のあらゆる知覚存在にとって有益なAGIの実現を目指しています。この崇高な理想を達成するために、私たちは日々努力を重ねています。しかし、Hyperonを活用した実用的な商用アプリケーションの開発が、この理念と矛盾するのではないかと考える人もいるかもしれません。しかし、私たちはそうは考えていません。むしろ、今日の素晴らしいオープンソースソフトウェアネットワーク、例えばLinuxオペレーティングシステムやインターネットを構築する上で、商用開発が果たしてきた重要な役割を十分に理解しています。重要なのは、オープンソースコミュニティが商業ユーザーや開発者と密接に連携して活動するだけの活力とエネルギーを持っていることです。現代のテクノロジー経済においては、商用世界と純粋な研究開発世界との相互作用こそが、最も驚くべき成果を生み出す原動力になっています。
上記を踏まえて、本稿の著者の一部は、TrueAGIという企業に携わっていることをお伝えします。TrueAGIは、Hyperonを活用し、様々な垂直市場における企業のAIニーズを満たすことを主要な目標としています。また、姉妹会社のZarqaは、Hyperonを利用してChatGPTのような商用チャットボットシステムを改善し、LLMを強化することを目指しています。これら以外にも、先に触れたHyperonと他のAIツールをゲノム推論に活用するRejuve Biotechや、Hyperonをメタバースエージェントの運用に利用するSophiaverseが存在します。これらのプロジェクトは全てSingularityNETエコシステムと連携しており、Hyperonが成長し拡大するにつれて、今後さまざまな企業が商用アプリケーションとして活用していくことを期待しています。
このような商用プロジェクトは、開発者への資金提供、機械学習実行に必要なコンピュータリソースの確保、そして一般の人々の日常生活にディープラーニングなどの高度なAIツールを結びつける使いやすいスケーラブルなアプリケーションの構築という点で、大きな役割を果たします。しかし、同時に複雑な課題も伴うことを認識しています。
商用プロジェクトには、技術面や設計面の課題があります。TrueAGIのCOOであるRobert Werkoは、 商用開発においては、研究用ソフトウェアシステムよりも優先度が低い、いくつかの要素に注意を払う必要があると指摘しています。具体的には、より厳格な機能優先順位付け、製品と市場の適合性、ユーザーフィードバックの収集、ユーザーオンボーディングの容易さ、ユーザーエクスペリエンスの品質、セキュリティとコンプライアンスなどが挙げられます。 一方で、確固たる商用ソフトウェアフレームワークを構築することは、研究開発を効率的かつスケーラブルに実行する能力を高めることができます。
さらに、技術や設計面以上に難しいのは、人間的および倫理的課題です。商用企業は「人々に役立つAGI」 のような崇高な目標だけを追求することはできません。 常に少なくとも所有者や株主の利益にも配慮する複合的な動機を持つことになります。しかし、ベン・ゲーツェルは次のように述べています。初期段階のAGIシステムの商用アプリケーションを倫理的に追求することは、そのAGIシステムの道徳的側面だけでなく、他の側面においても利益をもたらすと考えています。つまり、AGIが成長する過程で学ぶべき重要な要素の一つは、日常生活において現実的なことを成し遂げるための倫理的直感と実用的な活動とのバランスを取る方法です。
Hyperonの商用化に向けた初期段階の探索は、SingularityNETエコシステムの一部の企業との非独占的なコラボレーションで行われる予定です。これらの企業は、これまでにOpenCogアプローチを長期間にわたって実験してきた実績があります。具体的には、ロボットSophiaを持つHanson Robotics、介護ロボットのGraceを持つAwakening Health、AIを活用した音楽プロジェクトを手掛けるJam GalaxyとMusaicによるロックミュージシャンロボットのDesdemonaなど、ヒューマノイドロボットやアバター関連が挙げられます。
Graceロボットは現在、汎用LLMとカスタムプロンプト、特別に訓練されたTransformer型ニューラルネットワーク、そしてOpenCog Classicシステムによるセマンティック処理やメモリ管理などを含む複雑な対話システムによって制御されています。現在、OpenCog ClassicからHyperonへの移行作業が進められています。ヒューマノイドロボットに必要な言語、認知、行動といった様々な感覚入力の統合は、Atomspaceの統合能力が活かせる難しくもあり理想的なユースケースです。
Mind Childrenと呼ばれる新しいプロジェクトでは、身長約1メートルほどのヒューマノイドロボットを使用し、Graceと同様のソフトウェアアーキテクチャをベースとしつつ、最初からHyperonを採用する予定です。このプロジェクトでは、より一層、移動、行動計画、そして物理オブジェクトとのインタラクションに重点を置きます。
Rejuve BiotechとRejuve Networkのプロジェクトでは、すでにHyperonをバイオインフォマティクスデータ分析の一部に活用しています。具体的には、Flybaseオントロジーは分散型アトムスペースの初期テストケースとして利用されました。これは部分的に、Rejuve Biotechが長寿のキイロショウジョウバエのゲノムデータを分析する上で価値があるためです。Rejuve BiotechのAI責任者であるMichael Duncanは、次のように述べています。
バイオAIには、現在のLLMだけでは不十分な明確な理由がいくつかあります。
- 研究文献の偏り:現在の研究論文には、ごく一部のヒト遺伝子が過剰に研究されていることや、既存の科学パラダイムの制約など、さまざまなバイアスが存在します。こうしたバイアスはLLMの訓練データにも反映され、偏ったデータに基づく学習により、革新的な発見を導き出すよりも、既存の仮説を強化する結果に陥りやすくなります。特に、人体のような複雑な生物システムはまだ十分に理解されていないため、この問題は深刻です。
- 数理シミュレーションの構築能力の欠如:バイオAIにおける重要な役割の一つは、問題に関連する数値シミュレーションを構築することです。単に質問に答えたりパターンを特定したりするだけでなく、複雑な多段階推論を必要とするシミュレーションの設計と実行も求められます。これは、LLMが苦手とする分野であり、バイオAIにおけるLLMの限界の一つと言えます。
- 幻覚問題:LLMはよく根拠のない事実を生成する「ハルシネーション問題」を抱えています。
- 生物学的現実との接地不足:LLMは、生物学的概念を現実世界の生物学的文脈に裏付ける重要な直感を欠いています。これは、実験機器やデータセットなどの生物学的な要素との接点がないためです。
5.4 有益なAGIの達成
ChatGPTの登場以来、AGIの潜在的なリスクとメリットは非常にホットで議論を呼ぶトピックとなっています。しかし、Hyperonプロジェクトに関わる私たちの多くの人は、何十年も前からこれらのトピックについて深く考えてきました。その思考は、一般的なメディアで見られる浅薄な考察をはるかに超えて、システムアーキテクチャに深く浸透しています。
ベン・ゲーツェルは、Hyperonプロジェクトの様々な側面を形成する上で重要であった、AGI倫理に関する自身の見解の一部を次のようにまとめています。
Hyperonに携わる人々は、AGI倫理に関する問題に対して多様な見解を持っています。統一された「思想」が存在するわけではなく、議論は活発に行われています。しかし、初期のHyperonプロジェクトに携わった多くのメンバー、そして私自身を含め、共通して支持するいくつかの核心的な仮説が存在します。これらの仮説は、「初期Hyperonプロジェクト」におけるAGI倫理への基本的なアプローチを構成するものであり、以下に概要をまとめます。
- 技術の将来的な影響は保証できない:AGIのような根本的に革新的で幅広い用途を持つ技術の将来的な影響を確実に保証することは困難です。
- 様々な先端技術の将来予測も困難:現在世界中で活発に開発が進められている、ナノテクノロジー、バイオテクノロジー、ブレイン・コンピュータ・インターフェースなど、様々な技術についても、将来的な影響を確実に予測することは困難です。これらの技術とAGIとの融合も重要な論点であることは言うまでもありません。
- 開発は止まらない:経済的および人間的利益をもたらすなど、様々な理由からAGIや他の高度な技術開発を一時停止したり大幅に遅らせることは現実的ではありません。開発を遅らせる国は、開発を進める国に対して経済的および軍事的劣勢に立たされるでしょう。
- ネガティブな未来予測は根拠に乏しい:AGIが人間レベルまたは超知能に達した場合、必ずしもネガティブな結果が訪れるとは限りません。ハリウッド映画のような描写を根拠にするべきではありませんし、ニック・ボストロムの「スーパーインテリジェンス」のような議論も、ベン・ゲーツェルが数年前の詳細な論考で述べたように説得力に欠けます。
- 人工超倫理心は可能:人間は知性を持つ存在ですが、物理法則上、実現可能な最良の知性体である可能性は低いです。人間の脳は知能の限界に達している可能性が高く、同様に倫理的にも限界があると考えられます。「人工超知能」と同じように「人工超倫理心」も十分に可能であると考えられます。
- 危険性と知性の分離:怒り、嫉妬、自己中心主義など、人間同士を危険にさらす要素は、必ずしも人間レベルの知能に不可欠なものではありません。そうした要素は、進化の過程でたまたま備わった要素かもしれません。
- 倫理的AGIの構築可能性:他の知性を持つ存在に対して、強い思いやりと安定した倫理観で接するAGIの認知アーキテクチャの構築は、十分に実現可能だと考えられます。
- 初期AGIの活用による倫理的バイアス:直感的に、初期段階のAGIシステムを医療、教育、オープンサイエンス、芸術など、慈悲深く有益な分野で活用することは、人間や他の感情を持つ存在に対する思いやりのある態度を、これらのAGIシステムの心に植え付けることにつなのではないかという考え方があります。
- 分散型インフラの重要性:最初に出現する強力なAGIが、少数の個人や組織(国家や企業のリーダー)によってではなく、より多くの人間によって制御される方が、倫理的に望ましい結果が得られる可能性が高くなります。これは、人間の世界でも「権力は腐敗する傾向を持ち、絶対的な権力は絶対的に腐敗する」という格言に通じます。そのため、SingularityNETとNuNetやHypercycleなどのエコシステムプロジェクトが開発している分散型AGIインフラの重要性が高まります。
- 現在の倫理観への対応:現在の倫理基準は、人間中心に設計されているため、AGIシステムにとって必ずしも自然なものではないかもしれません。ただし、人間と同等レベルのAGIにとっては、特に習得や対応は難しいものではないでしょう。実際、現時点のLLMは人間レベルのAGIには及ばないものの、人間の倫理的判断を予測することに関してはかなり優れています。
これらのポイントのうち、最後のもの以外は、過去数年および数十年間に発表されたゲーツェルの論文の中で詳しく考察されています。例えば以下の論文などを参照してください。
- 高度なAGIに人間的な価値観を基づく倫理体系を注入する:2つの提言:Infusing Advanced AGIs with Human-Like Value Systems: Two Theses
- スーパーインテリジェンス:恐怖、約束、可能性:Superintelligence: Fears, Promises and Potentials
- 友好的なオープンソースAGIの開発を促進する9つの方法:Nine Ways to Bias Open-Source AGI Toward Friendliness
この最後の点については、最近の記事でGPT-4、LLaMA、その他のLLMを用いた実験が取り上げられ、特にさまざまなシナリオにおける倫理的な判断を予測する能力が検証されました。その結果、LLMはこのタスクに非常に優れており、高度な倫理観と慈悲心に基づいた行動を予測する能力において、大多数の人間を上回ることが分かりました。
ベン・ゲーツェルは、AGI-23の講演で次のように述べています。これらの実験を通して、人間が直面する倫理的課題は、道徳的に正しい行動に関する知識の欠如ではなく、むしろ自己利益や集団利益を倫理的考慮よりも優先させる傾向にあることだと気づかされました。LLM自体には意思決定能力や道徳観はありませんが、一般常識に基づいて倫理的な判断を予測する能力を備えています。さらに、要求されれば、非倫理的な行動に対するもっともらしい言い訳も生成できます。悪意を持って状況を誤解させ、その誤解に基づいて非倫理的な行動を提案したり、実行させようとする対抗的な試みに適切に対処するためには、更なる改善が必要です。いずれにせよ、現在の人間の倫理がどのような基準を持っているかという基本的な知識は、LLMを認知プロセスの一部として効果的に活用できるAGIシステムにとっては問題にならないでしょう。
全体として、AGI倫理における最も困難な課題は、AIが人間の倫理を理解することではなく、誤解を誘発する敵対的な策略に対処し、倫理的知識と日常的な意思決定における現実的な側面とのバランスを取ることであることが明らかになりました。従来、多くの人々は人間の倫理はあまりにも複雑で矛盾しており、形式化することはできないと主張してきましたが、LLMはこれら微妙なニュアンスを独自の方法で捉え、理解する能力を示しています。
この考察から導かれる重要な結論は、AGI向けの目標指向認知アーキテクチャ開発において、LLMを人間倫理のオラクル(助言者)として活用することは極めて有用と考えられます。ただし、LLMの回答を検証するためにはPLNのようなツールを使用することが不可欠です。さもなければ、敵対的な操作によってLLMが操作され、その信頼性が著しく損なわれる可能性があります。
このような考察を踏まえると、Hyperonのハイブリッドでマルチコンポーネントな構成は、AGI倫理にとって重要な資産に可能性を秘めています。Hyperonシステムは、人間の常識に基づく倫理的判断を模倣するように微調整されたLLMを「脳葉」として組み込むことができます。この脳葉を用いることで、実行しようとする行動の倫理的価値を人間基準で評価し、さらにその評価に基づいて、一般的な人間基準に基づく倫理的正しさを、最上位の目標の一つとして設定することが可能になります。
Hyperonシステムにおける適切な倫理観や価値観の導入は、人間の発達と同様に一度きりで達成できるものではなく、継続的なプロセスとなります。このプロセスには、以下のような多様な要素が含まれます。
- Hyperonシステムの目標に人間的な倫理判断を適切に組み込むこと。
- 思いやり、幸福、成長、選択といった普遍的な価値観に基づいて、Hyperonシステムが独自に価値観を探索し、発展させることを奨励すること。
- 初期のHyperonシステムが実行するアプリケーションは、全体としてポジティブな影響を与えるように設計する必要があります。これは学習過程でシステムを有益な方向へと導き、人々が自分自身の心を良い方向へ導くための探求を助けることを意味します。
この分野からは学ぶべきことが多く、間違いなく開発にあたる人間グループの精神と倫理観は、最も重要な要素の一つとなるでしょう。
6. 結論
今後数年間、例えば今後3年から10年ほどの間に、人間レベルのAGIを達成できる二度とないチャンスが訪れるように思われます。正確な時期は予測できませんが、大規模なHyperonシステムを構築し、さまざまな分野で適切な相互作用を通じて学習させることで、人間レベルの汎用知能に近づけることが、少なくとも理論上可能であると考えられます。
上記の通り、現実的にHyperonシステムに教え込むことが可能な能力の一つとして、ソフトウェアの設計とコーディングがあります。LLMはすでに単純な状況下でこのタスクをこなすことができます。Hyperonでは、この能力をさらに拡張し、より深い創造性と高度な多段階推論を実行できるように設計されています。システムが一度自らを改良し、次世代バージョンを書けるほど十分なコード設計とコーディングができるようになれば、本格的な知能爆発と技術的特異点、つまりシンギュラリティが訪れる可能性のある領域へと突入することになります。
まだ、シンギュラリティをもたらすような、急激な自己改変が可能なAGIは開発できていませんが、Hyperonの開発は非常に興味深い段階を迎えています。MeTTaインタープリタと分散型アトムスペースの初期バージョンが完成しており、実験や開発を進めることが可能になっています。そして、お伝えしたように、アルファ版のリリースは暫定的に2024年第1四半期末を予定しています。
システムのスケーラビリティはまだ開発中で、包括的なツールやドキュメントも充実していませんが、これらはいずれもロードマップに含まれており、近いうちに提供される予定です。アルファ版のリリース時には、経験豊富なAGI研究者はもちろん、熱心なAI開発者、アプリケーション開発者など、オープンソースコミュニティへの幅広い人材参画を期待しています。真に有益なAGIの実現に向けた急速な進歩の可能性は計り知れません。
HyperonとCogPrimeは、いずれも複雑な設計であり、その完全な理解は開発者全員にとっても現在進行中の課題です。今回の記事では、ハイライトを紹介し、読者の皆様がより深く理解したいと興味を持っていただくことを目的としました。こちらのリンクからアクセス可能なドキュメント、ビデオ、コードをより深く探求していただくきっかけになれば幸いです。
<前編へ戻る>
【よく読まれる人気記事】
カルダノステークプール【OBS】
暗号通貨革命では、カルダノステークプール(ティッカー:OBS)を運営すると共に、皆様に役立つ有益な情報を無償で提供して行きます。ADAステーキングを通しての長期的なメディア&プール支援のご協力の程、何卒よろしくお願い致します。
