OpenCog Hyperon:人間レベルを超えるAGI(汎用人工知能)のためのフレームワーク<前編>
OpenCog Hyperon(オープンコグ ハイペロン)の概要
2008年にリリースされたOpenCogは、ソフトウェアとハードウェアを組み合わせて心の働きをシミュレートするオープンソースプロジェクトであり、AGI(汎用人工知能)の実現を目指しています。脳を直接リバースエンジニアリングするのではなく、コンピュータ科学に基づいた工学的なアプローチを採用している点が特徴です。その認知アプローチは、心の哲学、認知科学、コンピュータ科学、数学、言語学など、多岐にわたる学術分野の融合に基づいています。
OpenCogは、Atomspaceと呼ばれる高度な知識グラフを中心に、ニューラルネットワーク、生成AI、確率的AI、プログラム学習AIなど、さまざまなAIモジュールを統合します。この統合により、適切な認知アーキテクチャを通じて異なる知能コンポーネントが相互に支援し合い、創発的な構造とダイナミクスを生み出す「認知的シナジー」を実現します。
また、OpenCogはオープンソースプロジェクトであり、誰でもコードを閲覧したり、貢献したりすることができます。
2021年に再構成されたOpenCog Hyperonは、OpenCogプロジェクトの拡張版であり、スケーラビリティと使いやすさの課題を解決し、新たな数学的概念を用いて、より強力で汎用性の高いAIの実現を目指しています。2024年4月30日には、Hyperonのアルファ版がリリースされており、最新のAI言語「MeTTa」を導入し、学習空間と知識ストアを提供することで、パターンマイニングや注意配分などのツール群を活用し、AIシステムが協調して学習し問題を解決することが可能になります。
Hyperonは、SingularityNET、HyperCycle、AI-DSLと協力し、全てのAIエージェントが互いに通信できるメタサービスの集合をサポートするフレームワークとして機能し、部分の総和よりも大きいAGIシステムを形成します。
人工知能 人類最悪にして最後の発明:ジェイムズ・バラット(著)
OpenCogについては、2015年6月に出版された『人工知能 人類最悪にして最後の発明』第11章「学習する認知アーキテクチャ”OpenCog”」にて、最初にAGIを達成する可能性のある数少ない組織の一つとして、ベン・ゲーツェル氏と共に紹介されています。
AGIやASIのコントロール問題をテーマにした作品としては、ニック・ボストロム氏の著書『スーパーインテリジェンス:超絶AIと人類の命運』が主要な参考文献となりますが、難解なそれとは異なり、こちらは初心者でも理解しやすい内容となっています。SingularityNETのTGEが行われた2017年頃からの古参の皆さんはすでに購読済みだと思われますが、興味がある方はぜひチェックしてみてください。AGIの研究開発に関する歴史的な知識や、これから紹介するHyperonの専門的な論文の内容も理解が深まると思います。
当時のプロモーション映像
参考文献
OpenCog Hyperonは、人間レベルを超えるAGIの構築を目指したフレームワークです。このフレームワークの詳細については、2023年9月19日に発表された以下の論文をご覧ください。論文は100ページに渡る長文ですが、今回これを2回に分けて翻訳して紹介します。内容は正確性と読みやすさに配慮して行う予定です。
論文タイトル:『人間レベルを超える汎用人工知能のためのフレームワーク:OpenCog Hyperon: A Framework for AGI at the Human Level and Beyond』
注意事項
- 翻訳はLLMを用いて行うため、内容に誤りがある可能性があります。
- 翻訳結果については、専門家のレビューが必要です。
1. はじめに
AI分野は、20世紀半ばの黎明期に、人間レベルかそれ以上の汎用知能を持つ機械の開発を目指して誕生しました。しかし、当初の予想よりも困難であることが判明すると、AI分野は大きく方向転換し、特定のタスクを効率的に遂行することに焦点を置いた「Narrow AI(特化型AI)」システムが主流となりました。これらのシステムは、より汎用的な能力や自己理解・世界理解を目指すものではありませんでした。
しかし、近年におけるコンピューティングパワー、センサーの性能、そしてデータの利用可能性の飛躍的な向上を受け、汎用人工知能(AGI)への熱意は再び高まり、過去最高レベルに達しています。今では、数年のうちに人間レベルのAGIが実現可能だという野心的な予測も珍しくありません。
この論文の著者たちは、世間一般でこのような見方が流行するずっと前から、AGIの実現可能性について楽観的な見解を持っていました。しかし、人間レベルもしくはそれ以上の汎用知能という壮大な目標を達成するためには、問題の繊細さに真正面から向き合うことが必要不可欠であると認識しています。人間レベルのAGIは、決してAGIの最終目標ではありませんが、相互に依存し合う多くの側面を持っており、現在のLLMを中心とした最先端言語モデルのような単純な認知アーキテクチャでは実現困難であると考えています。
ここでご紹介するのは、「OpenCog Hyperon」です。これは、自律学習と人間による教育や監督を組み合わせることで、我々が人間レベルを超えるAGIを達成できると考える認知アーキテクチャとAIシステムの設計です。HyperonはOpenCog系列の新しいシステムであり、初期の「OpenCog Classic」システムと同じ中核的な認知理論と上位設計概念に基づいて構築されていますが、より高いスケーラビリティ、使いやすさ、数学的洗練を実現するために最初から設計し直されています。本稿では、開発中のソフトウェアシステムであるOpenCog Hyperonシステムの概要と、その設計を中心に発展してきた様々な理論的・実践的な取り組みについて概説します。
AGIやAI分野に長年携わる方なら理解できると思いますが、Hyperonのような「ブランド化されたソフトウェアシステム」は、技術的な観点からは一見重要そうに見えますが、実際にはそれほど根本的な意義を持っていません。しかし、社会学、マーケティング、注目を集めるという観点からは、明らかに重要です。「OpenCog Hyperon」という名称の下で、私たちは多様なアルゴリズム、データ構造、数学的アイデア、認知システム理論、そしてコードを統合しています。これらは互いに密接な関係を持ちながらも独立した意味を持ち、Hyperonソフトウェアシステムの構築、利用、理解において共通して用いられます。以降の議論では、OpenCog Hyperonのコードベースと実用アプリケーションに特化した内容に加え、様々なソースから取り入れられた理論的アイデアや概念についても触れます。これらのアイデアや概念は、Hyperonの枠組みを超えても重要な価値を持っています。
本稿は主に、技術的な概要をハイレベルで概説しています。より詳細な情報については、OpenCog Hyperonのウェブサイトに掲載されているドキュメント、ビデオ、コードリポジトリをご参照ください。Hyperonの認知理論についてより深く理解を深めたい方は、ゲーツェルによる2021年の論文 『汎用知能の一般理論:General Theory of General Intelligence』 もご参照ください。
解説スタイルの簡単な注意書き:この文章は、 Hyperonの実現に向けて共に取り組んできた著者グループによる、堅苦しくない非公式の解説文です。今回は、少し珍しい構成を採用しており、三人称による文章と、プロジェクトに携わる様々なメンバーの一人称による直接引用を織り交ぜていきます。このような形式にしたのは、文章を堅苦しくなく、より人間味のあるものにしたいからです。また、この種の研究開発やエンジニアリングは、抽象的で顔のない活動ではなく、特定の人間のコミュニティの仕事、情熱、洞察力をぶつけ合い、シナジーを生み出す現実を伝えるためのものです。プロジェクトには、それぞれが独自の視点と個性を持って携わっています。
2. Hyperonへの道のりのスナップショット
この論文の核心は、Hyperonソフトウェア研究開発プロジェクトにおけるAGIへの具体的なアプローチの概要説明ですが、この技術プロジェクトを「我々が構築するかもしれない心とは何か」という、より広範な理解の追求の中に適切に位置づけることが重要だと考えています。
今日のAI、あるいはある程度のAGIも、主要な商業的・実践的な追求の対象となっており、この分野の新規参入者の多くは、利用可能な素晴らしいツールで今すぐ何ができるかに焦点を当てています。しかし、OpenCogプロジェクトは、AI分野における以前の段階、つまりハードウェアとデータリソースがこのような迅速な実験をサポートするのに十分でなく、主に概念的な探究によって推進されていた時代から生まれました。つまり、AI研究開発は、知性の本質を理解するという知的探究と深く結びついていたのです。
2.1 Hyperonにおける知性の概念:いくつかの考察
2023年6月、ストックホルムで開催されたAGI-23カンファレンス内のHyperonワークショップにて、Hyperonの共同創設者であるベン・ゲーツェルは、Hyperonシステムとその前身システムの基礎となっている汎用知能の概念について、自身の考え方を振り返りました。ベンの考え方は非常に重要ですが、Hyperonのようなシステムは一人の産物ではなく、その誕生過程や存在理由について異なる見解があることも留意する必要があります。
1970年代初頭、SFや科学普及誌でAIについて読み始めたのが、私とAIとの関わりの始まりでした。しかし、70年代後半から80年代初頭にかけて、当時のAI研究が主にルールベースの生産システムに依存しているように見えたため、次第に幻滅を感じるようになりました。これらのシステムは論理そのものが嫌いだったわけではないのですが、人間のような認知に必要な全ての知識を、手作業でコード化する発想がナンセンスだと感じたのです。しかし、実際に自分でAIシステムのプログラミングを始めるにつれ、なぜAI分野がそのようなシステムによって支配されていたのか理解できるようになりました。自己組織化システムで成果を上げることは、非常に困難だったのです。
10代後半にAI分野を最初に学んだ時、もう一つ興味深い側面を発見しました。それは、特化型AIの驚くべき実現可能性でした。当時の限られたコンピューティングリソースでも、私より上手にチェッカーをプレイするAIシステムが存在することは、ティーンエイジャーの私にとって非常に印象的でした。これが、特化型AIとAGIの間の二分法に関する厄介な疑問を提起しました。1960年代から70年代にかけて、人間が行うと高度な汎用知能が必要に見えるタスクが、実際には非常に単純なアルゴリズムでうまく行えることが判明したのは、決して些細な発見ではありませんでした。人間にとって進化上重要だった様々なタスクをこなす特化型能力の寄せ集めこそが、人間レベルのAGIかもしれないと考え始めた研究者がいたのも納得できました。
一方、AI分野の進化に伴い、実用的な問題解決において、必ずしも単純な特化型技術ではなく、よりAGI志向のアプローチを採用する方が効果的な場合が出てきています。これは、実世界のアプリケーションで問題となるような厳しい時間とリソースの制約下でも当てはまります。
人間と機械の知能の数学を理解することを目指して数学の博士号を取得する過程で、私は汎用知能の概念を形式化することに取り組みました。1991年の著書『知能の構造:The structure of intelligence』では、汎用知能を「複雑な環境下で複雑な目標を達成する能力」と定義しました。その後、アルゴリズム情報理論に基づいて関連する複雑性の概念を形式化しようとしました。これは、2007年頃にLeggとHutterが提唱した汎用知能の形式的定義と近いアプローチです。この定義に従うと、特化型AIは、一般的に単純な範囲の目標を追求する傾向があり、人間や他のソフトウェアシステムによって十分に準備され管理された環境で最も効果的に動作します。
ずいぶん後になって、ブリュッセル自由大学で2018年に博士論文『オープンエンド・インテリジェンス:Open-Ended Intelligence』を執筆したWeaver(別名:David Weinbaum)に出会いました。Weinbaumは大陸哲学の視点からこのテーマに取り組み、 知能を複雑で自己組織化し、自己生成(自己再構築)するシステムとして考察しました。彼の見解では、知能システムは「個体化」を目指しています。これは、システムが境界を維持して存在を継続させながら、同時に自分を超えた何かへと進化することを目指すことを意味します。彼は、目標を達成したり報酬関数に向かって働くことが、システムを賢くする核心ではない。むしろ、個体化と自己超越に向かう自己組織化ネットワークこそが、時に(明示的または暗黙的に)目標を生み出し、それらの目標を最大化させるような行動をとらせるのだと主張しています。しかし、この自己組織化は、 目標が消失し、新たな目標が浮上する原因にもなり得ます。これは、目標志向の人間である私自身の経験とも共鳴します。 私は頻繁に目標を設定しますが、追求していく過程で、目標を再定義したり、放棄したりしがちです。
Weaverの知能概念は、科学的・数学的に厳密なものではありませんでしたが、部分的には印象論的な要素を含みながらも、AGI理論と複雑系理論を結びつける非常に納得のいくものでした。彼のオープンエンド・インテリジェンスという概念においては、目標達成は知能の中核をなすものではありません。むしろ、焦点は自己組織化の側面にあります。例えば、知能システムは特定の時点で報酬関数に向かって働くことがありますが、それが本質的にシステムを知的にするわけではありません。代わりに、個体化と自己超越に向かう自己組織化ネットワークは、時に暗黙的または明示的な目標を生み出す可能性があります。そして、その目標を最大化するように行動することもありますが、目標を消滅させ、新たな目標を生み出すこともあります。この目標形成と自己超越の追求というダイナミックな性質は、私自身の歩んできた人生にも通じるものだと感じられました。
Weaverの知見は、従来の「複雑な環境における複雑な目標達成」という汎用知能の定義にとらわれていた私にとって、新たな視点を提示してくれました。その結果、AGIに対する多様な見方に心を開くようになり、AGIは必ずしも厳密な定義が必要ではなく、多面的で捉えどころのない概念かもしれないとも考えるようになりました。
Hyperonは、複雑な環境下で複雑な目標を達成することを目指したシステムです。この目標には、明示的に設定されたものだけでなく、自己組織化の過程で暗黙的に生じるものも含まれます。さらに、Hyperonはオープンエンド・インテリジェンスとして、自己組織化と自律性を追求する過程で、持続的に個体化と自己超越の両方を達成することを目指しています。
Hyperonを支えるAGIの概念的アプローチでは、人間レベルの汎用知能は、より高度な汎用知能システムへの道のりにおける、ある意味で任意の通過点に過ぎません。Hyperonの基本アーキテクチャは、人間の認知科学から多大な影響を受けていますが、人間の心や脳を細部まで模倣しようとはしていません。その結果、Hyperonは人間レベルの合理性、洞察力、分析能力、創造性、そして倫理観や思いやりといった、人間らしさに縛られることはありません。「複雑な環境下で複雑な目標を達成する」とか「個体化と自己超越のバランスを取る」といったAGIに関する汎用的な概念は、人間の行為の多くを的確に説明していますが、同時に、これらは人間が他の実現可能な物理システムと比較しても、せいぜい「まあまあ」程度の能力しかない分野でもあるのです。人間と互いに理解し、関係を築くことができるAGIを開発することは人類にとって重要ですが、Hyperonは人間レベルをはるかに超える様々な知能形態と共存しながら、これを達成することができるような設計を目指しています。
2.2 「作れる心」とは何か?
引き続き、AGI-23カンファレンスの講演内容に話を戻すと、ベン・ゲーツェルは以下のように語っています。
10代だった頃、汎用知能の本質を理解しようとする探究は、私をAIだけでなく、心の哲学へと導きました。それは非常に難解なものでしたが、いくつかの点において明確な指針を与えてくれました。実際、OpenCog Hyperonの設計に向けた私の旅は、技術的なAIというよりもむしろ心の哲学から始まったのです。
私の考え方に大きな影響を与えた哲学者の一人に、19世紀後半のアメリカの哲学者チャールズ・サンダース・パースがいます。彼は量指定子論理を導入したことで知られ、AIの基礎となったいくつかの技術的要素にも貢献しています。パースの「形而上学」は、彼が第一、第二、第三と呼んだ3つの基本的なカテゴリーから発展しました。第一は、分析不可能な純粋な生の経験です。第二は、ビリヤード球同士の衝突のような反応、つまり物理世界を表します。そして第三は、あるものが他のものと関係している関係性です。
これらのカテゴリーは、様々な解釈が可能です。まず第一のカテゴリーは、デイヴィッド・チャーマーズが意識の分析で論じた原始的意識体験に結びつく可能性があります。パースは、この現象論的体験と複雑な意味論的関係との間の関係を、難問ではなくカテゴリーの誤りであると見なしました。彼の見方は、純粋な体験(第一)、組織化されたパターン(第三)、そして身体的反応(第二)は、互いに還元できない別個のカテゴリーであるというものでした。
パースは習慣に関する概念も持っていました。彼はそれを「精神の法則」と呼び、習慣を形成する傾向のことだと考えました。つまり、あるパターンが世界の中で一定期間出現し続けると、それが再び現れる確率は、そうでない場合よりも高くなるというものです。このパターンという概念は、パースにとって根本的なものでした。
パースにインスピレーションを受け、 私は知能システムと心はパターンが織りなす集合体として考えるようになりました。これらのパターンは、自分自身と世界のパターンを認識し、互いに影響を与え合いながら、ランダムに変異や結合していくのです。 そして、本質的にこういったパターンが心を構成し、自己組織化システムとして機能します。 グレゴリー・ベイトソンなどの哲学者や、ベンジャミン・ウォーフなどの言語学者も、世界を自己組織化のパターンシステムとして捉えるという、 同様の見解を示しています。
これらの心の哲学と複雑系科学からのアイデアは、ゲーツェルが1990年代に出版した一連の書籍の中で詳細に具体化されました。
- 知能の構造:The Structure of Intelligence
- 進化する心:The Evolving Mind
- カオス論理学:Chaotic Logic
- 複雑性から創造性へ:From Complexity to Creativity
これらの書籍には、AI設計のハイレベルな概要も含まれていましたが、実際のシステム実装には多くの困難な決断を伴うため、具体的に直接的に実装できるものではありませんでした。
このような哲学的思考、認知科学、システム理論に基づくAGIに関するアプローチは、単一のAGI設計を決定するのではなく、実現可能なAGI設計や、部分的・完全に機能するAGI、あるいはプロトAGIシステムを考えるための手法を提供します。また、高度なレベルのAGIを実現する可能性が高いAGI設計と、そうでない設計を見極めるための指針を与えてくれます。
2.3 Hyperon前史の一部
引き続き、ベン・ゲーツェルのAGI-23カンファレンスでの講演では、このような概念的探究がいかにして一連の実用的なAIソフトウェアシステムの構築へと導いたのか、具体的に説明されました。そして、その集大成がHyperonと呼ばれるプロジェクトです。
1990年代初頭、私はHaskellの初期バージョンを使って、自己組織化パターン認識に基づくシステムの構築にかなりの時間を費やしました。これらは興味深い試みではありましたが、実用的なアプリケーションには至りませんでした。問題の原因はスケールの不足なのか、それとも根本的にアプローチ自体に問題があるのか、当時私は考察していました。数千億ものニューロンを持つ人間の脳の圧倒的な大きさは、スケールがこそが重要な要素であることを示唆していました。
その後、私はインターネットを活用することで、これらのシステムを大規模にスケールアップさせる可能性に気づきました。1990年代後半のウェブマインド計画は、インターネットを活用し、大規模な自己組織化パターン認識エージェントを実行することを目指していました。私の著書『インターネット・インテリジェンスの創造:Creating Internet Intelligence』 では、そこから出現する「グローバルブレイン」の概念、特に分散コンピューティングネットワーク上に存在する強力なAGIシステム(Webmindインスタンスなど)が、集中型グローバルブレインの認知ハブとして機能する可能性について論じています。
1995年には、私は「分散主義」を掲げてアメリカ大統領選への出馬を表明するウェブページも公開しました(当時はまだ35歳になる前で、2001年まで出馬資格がありませんでしたが)。私の著書『インターネット・インテリジェンスの創造』では政治的な側面は強調しませんでしたが、背景にはそういった考えがありました。ブロックチェーンが登場するずっと以前から、私や他の人々は大規模なAGIを構成する分散型AIプロセスの分散制御の必要性、そして初期段階のAGIを狭い目的を持つ中央集約型組織の手に渡らないようにする重要性を認識していました。
初期の仮説的な設計では、世界規模に分散されたWebmindシステムと、それに関連する人工生命体システム(WebWorlds)を想定していました。これらは、現在のTODAのような分散型台帳を必要としない技術を強く彷彿させる、強力な暗号化と分散処理を利用するものでした。(全てのトランザクションを記録した巨大な複製台帳という概念は、スケーラビリティの問題が明白であり、私には思い付きもしませんでした)しかし、当初は分散型グローバルコンピューティングシステムの最初のアプリケーションとして、分散型通貨を利用することは考えていませんでした。一時的に検討はしましたが、MastercardやVisaに対抗できるほど高速なシステムを構築するには、長い時間がかかるように思えたのです。過去には金融取引システム向けのAI開発にも携わっていましたが、分散型通貨が一部の闇市場的な新たな投機的地下経済の中心になり得るということは思い付きませんでした。もしそう考えていたら、私はサトシ・ナカモトになり、Hyperonははるかに資金力のあるプロジェクトになっていたでしょう!
当時の技術基盤では、Webmindのような分散型エージェントシステムによる実用的なAGIシステムの構築は困難であることが判明しました。このため、哲学的にはWebmindと似ていますが、ソフトウェア構成としては現在のHyperonに近い、Novamente認知エンジンが誕生しました。Webmindは分散型エージェントシステムに焦点を当てていましたが、Novamenteはより構造化されたものでした。どちらのシステムも、論理的推論、非公理的推論システム、進化型プログラム学習、注意配分、パターンマイニングを統合することを目指していました。
Novamenteは、Atomspaceと呼ばれる知識ベースを中心に構築されていました。Atomspaceは、当初「汎用ハイパーグラフ」と呼ばれていた構造で、後に「メタグラフ」と呼ばれるようになりました。簡単に説明すると、ノード同士をまたぐリンクや、リンク自体を指すリンク、さらに大きなサブグラフを指すリンクを備えたグラフです。また、ノードとリンクの両方に対して、さまざまな複雑な重み付けや構造(複雑な型システムから生じる型のようなもので、メタグラフ自体としても表現できる)をラベル付けすることができます。このフレームワークでは、ノードとリンクのどちらも「アトム」と呼ばれます。Webmindも同様の表現能力を持っていましたが、Novamenteほど明確で洗練された方法ではありませんでした。
Novamenteのチームは、私を中心に、Cassio Pennachin、Hyperonで現在中心的な役割を担っているAndre’ Senna、精力的にNARS AGIプロジェクトを率いているPei Wangなどによって結成されました。我々は、Atomspace上で動作するエージェントとして、さまざまな認知プロセスを実装しました。基本的に、我々は2つのループの入れ子構造を逆にして再構築しました。当初の構造では、外側のループがエージェントを反復処理し、各エージェントが個別の機能を実行して、集合的に認知プロセスを担っていました。 一方、Novamenteではループの順番が逆転し、システムはAtomspace内のノードとリンクに対して作用する認知プロセスを反復処理するようになりました。
このようなアプローチの効率性は、使用されているハードウェアインフラによって大きく左右されました。例えば、私が1990年代半ばに短期間実験した、ダニー・ヒリスのコネクションマシ(最大128,000個の独立したプロセッサを搭載した並列コンピュータ)のようなMIMD並列ハードウェアでは、Webmind型のような設計が最適で効果的でした。一方、RAMメモリと処理系を厳密に分離した従来のノイマン型アーキテクチャを持つ典型的な現代のコンピューティングシステムでは、Novamenteのような設計の方が許容できる効率性を達成する可能性が高くなります。革新的な最新のハードウェア設計、例えばSimuliとTrueAGIで共同開発しているRAMメモリ内蔵プロセッサ型のAGIチップの場合、このような汎用AGIシステムを実装する最適なアプローチは、ある意味でWebmindとNovamenteの中間にある可能性があります。
Hyperonフレームワークは、WebmindやNovamenteとは異なり、実装における「分散型エージェント」の度合いに関して、非常に柔軟性のある設計になっています。これは過去20年間のコンピュータ科学とソフトウェア設計における著しい進歩のおかげです。もちろん、これはHyperonのMeTTaプログラミング言語(このプログラムはAtomspaceのサブネットワークであり、Atomspaceを変換するプログラムとして設計されています)が、Hypercycleのレジャーレスブロックチェーンでスマートコントラクト言語として使用されることと関連しています。
NovamenteAGIプロジェクトは、様々なAGIアルゴリズムに関する研究論文を発表し、特に自然言語処理や信号解析の分野で、限定的ながらも実用的な成果を上げることができました。2008年には、システムのかなりの部分がOpenCogとしてオープンソース化され、コミュニティによるコードベースの拡張が始まりました。中でも特筆すべき貢献の一つが、Linas Vepstasによって開発されたOpenCogパターンマッチャーです。当初、Atomspace知識グラフにおけるパターン認識システムとして開発されましたが、最終的には再帰的なパターンマッチング機能を備えた関数型および論理型プログラミングフレームワークへと進化しました。
しかし、OpenCogが進化するにつれて、スケーラビリティと使いやすさに関する課題が明らかになってきました。これらの課題に対処するため、一部の開発者はニューロシンボリックシステムの研究開発に着手しました。Alexey PotapovとVitaly Bogdanovは、深層学習ライブラリであるTorchをOpenCogを統合し、記号処理とニューラル処理を組み合わせることを可能にしました。しかし、この統合はあまり効率的ではないことが判明しました。OpenCogは、特にGPU上で実行する際に、最新のニューラルネットワークフレームワークよりも処理速度が著しく遅かったからです。
これらの課題が、私たちを現在OpenCog Hyperonと呼ばれているAGIインフラ設計へと向かわせる大きな要因の一つとなりました。
2020年頃のOpenCogは、拡張性と使いやすさの面で限界が見えていました。そこで、多くのOpenCog開発者は、システムをほぼゼロから再構築することを検討しました。この動きは、開発者が数学や理論の発展を取り込み、これらの成果をAIシステムに直接反映するという考えとも結びついていました。このような取り組みの中で生まれた概念の一つが「認知的シナジー」です。これは、人間の脳における異なるタイプの記憶や学習メカニズムがどのように相互作用するかを理解したことから生まれたものです。認知的シナジーは、脳が問題解決に行き詰まった際に、ある種の記憶から別の種類の記憶へと変換し、本質的に異なるタイプの学習メカニズムを活用して解決策を見いだすことを示唆しています。
宣言型知識 (事実や関係性を表現する知識)、手続き的知識(手順や操作方法に関する知識)、感覚的知識(感覚器官を通して得られる知識)の相互作用を形式化するために、圏論やその他の関連する数学概念が用いられ、様々なAIアルゴリズムをメタグラフ上の操作にマッピングされました。この数学的フレームワークをOpenCogに深く組み込むことで、効率化が現実味を帯びてきました。この概念的および形式的なアプローチは、OpenCogシステムとスケーラブルな深層学習フレームワークのような外部のAIシステムとの間に、より洗練され効率的なインターフェースを構築する点でも有望であると考えられました。
最終的に、これらの必要性とインスピレーションに基づいて、OpenCog Hyperonと呼ばれる新システムが誕生しました。Hyperonは素粒子の名前です。この名前は、Atomspaceで始まった物理学用語のメタファーテーマを引き継ぎ、Atomspaceが汎用ハイパーグラフ(別名:メタグラフ)であることから、hypergraphとの音の響きも考慮して選ばれました。
ここからは冗談半分になりますが、次の大規模なオーバーホールには「Tachyon(タキオン)」という名前が提案されました。これは、量子コンピューティング構造をコア部分に組み込んだり、クローズド・タイムライク・ループ(時間的閉曲線)を用いた斬新なハードウェアによる計算の高速化を取り入れるかもしれません!(しかし、それはまた別の文書での話にしましょう…)
3. OpenCog Hyperon:AGIのための現代的でスケーラブルなインフラストラクチャ
それでは、いよいよソフトウェアフレームワークとしてのHyperonについて詳しく見ていきましょう。図1は多くの主要コンポーネントの概略図を示していますが、これらのコンポーネント間の相互関係は非常に多様で動的です。そのため、すべてを簡単に正確に図式化することはできません。
3.1 AtomspaceとMeTTa:OpenCogのコアとなる構成要素
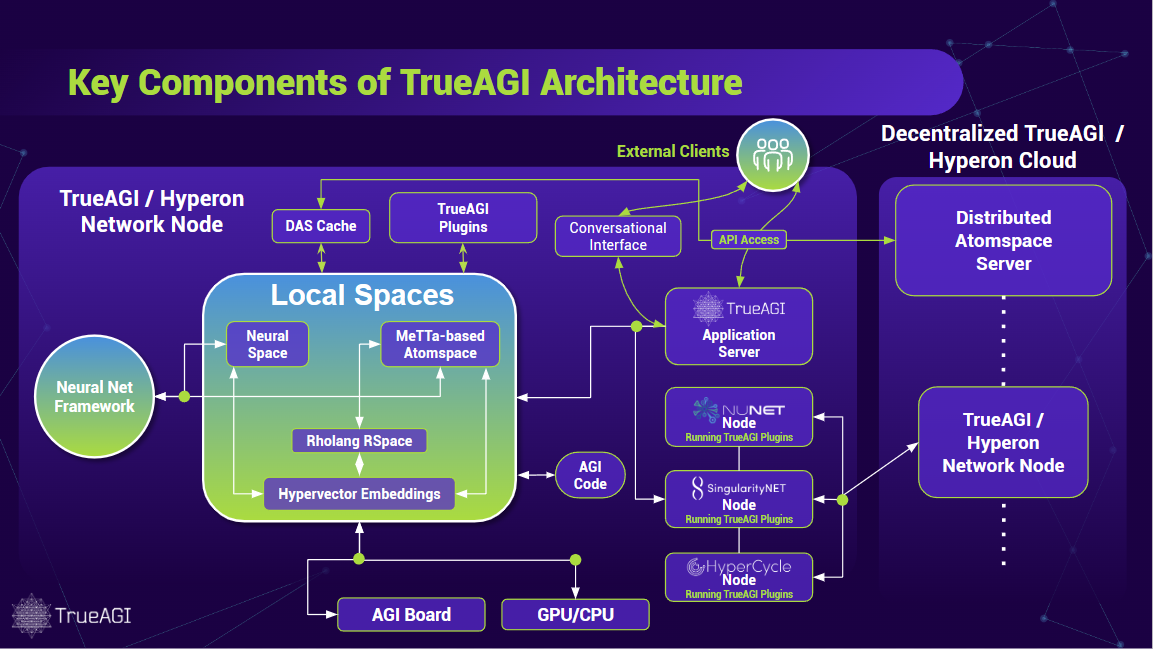
Hyperonの中核となる構成要素は、以前のOpenCogやNovamente認知エンジンと同様に「Atomspace」と呼ばれるメタグラフです。Atomspaceはノードとリンクで構成されるメタグラフであり、複雑な相互リンク構造を有しています。このメタグラフは非常に汎用性に優れ、ノードやリンクにサブグラフを含む様々なデータをラベル付けすることができます。このラベリングメカニズムにより、メタグラフ内に複雑な型システムを埋め込むことも可能になります。
Hyperonの新要素であり、従来のOpenCogバージョンとは質的に異なるのがMeTTaと呼ばれるプログラミング言語です。MeTTaプログラムはAtomspace内のサブメタグラフであり、Atomspaceの一部を変更または追加する手続きとして解釈されます。(補足説明:Atomspace内のすべてのサブメタグラフは、一種のMeTTaプログラムであり、MeTTaインタープリタによって何らかの命令として解釈されないすべてのアトムも、MeTTaプログラムで処理可能なデータの 「定数」項目です。)
Hyperon時代にOpenCog Classicと呼ばれるようになった以前のOpenCogバージョンには、Linas VepstasというOpenCogの英雄的開発者が設計し、実装した高度なパターンマッチャーが特徴でした。このパターンマッチャーは、従来の意味でのパターンマッチング以上の機能を持ち、パターンマッチング中にAtomspace上で様々な変換を実行する機能が追加されていました。これは合理的で興味深い設計でしたが、Hyperonでは少し異なるアプローチを取ることにしました。
- 標準的で静的なパターンマッチング機能への移行 : Hyperonのパターンマッチング機能は、より標準的で静的な設計に変更されました。ただし、特殊な機能もいくつか備わっています。例えば、変数を含むパターンの柔軟な処理、効率的な型推論を備えた型システムに属するアトムを含むマッチング、個々のアトムではなくサブグラフ全体に対する変数のマッチングなどです。
- MeTTaによるプログラムロジックの分離 : 従来のOpenCogでは、パターンマッチング機能自体に複雑なプログラムロジックが組み込まれていました。しかし、Hyperonではこのアプローチを変更し、パターンマッチャーをラップする新しい言語MeTTaを作成しました。この言語はパターンマッチングを呼び出す機能を持ち、パターンマッチャーの走査プロセス内ではなく外部でプログラムロジックを処理します。
MeTTaは、関数型プログラミングと論理型プログラミングの要素を取り入れつつも、既存のパラダイムの枠を超えた全く新しいタイプのプログラミング言語として誕生しました。
MeTTaはパターンマッチングに加えて、独自のセマンティクス(意味論)を持つ等式が組み込まれています。この等式の開発には多大な検討が重ねられました。ここでの目的の一つは、MeTTaをホモトピー型理論をはじめとする、同一性の概念に複雑さを与える数学モデルと統合することでした。MeTTaの等式に対する非正統的なアプローチは、代入や比較がどのように動作するかを決めつけない、十分低レベルなものです。
その基本的な性質から、MeTTaインタプリタはAtomspaceのメタモーフォシス(変態)と自己書き換えを可能にします。これは、自己修正コードにとって大きな可能性を示唆します。MeTTaインタプリタと連携したAtomspaceは、本質的に自己修正可能で自己書き換え可能なノードとリンクの集合と捉えることができます。
さらに、MeTTa言語は非常に汎用性が高く、メタグラフとMeTTaグラフの両方として表現することができます。メタグラフは、ノードとリンクだけでなく、それらの関係性も表現できるグラフ構造です。一方、MeTTaグラフは、MeTTa言語で表現されたグラフ構造です。
Alexey Potapovによると、Hyperon設計の初期段階では、独自のAtomspaceや関連ツールを構築するのではなく、既存のグラフストアやベクトルストアとそれに関連するクエリエンジンを利用することが検討されました。しかし、最終的にはAGIの要件があまりにも特殊であったため、独自の構築が必要であるという結論に至りました。
Hyperonにおける知識表現は、MeTTAプログラムを含め、全てメタグラフと呼ばれる構造で構成されています。これは、一般的なAIやAGIアプローチとは実質的に異なる点です。通常のグラフは「3要素の集合」で表されますが、ハイパーグラフは「タプル(複数の要素の集合)の集合」です。一方、メタグラフは「木(ツリー)の集合」であり、各エッジ(辺)はノード(頂点)の木構造的なつながり、あるいはエッジは任意の数のノードと他のエッジをつなぐタプルであると言えます。このメタグラフ表現は、複雑なステートメントや任意の知識表現に不可欠であり、プログラムコード表現にも適しています。
メタグラフは、通常のグラフのようなシンプルなデータ構造にエンコードすることはできますが、メタグラフエンコーディングを前提とした走査、インデックス付け、検索アルゴリズムには十分に最適化されていません。後者には補助ノードの導入が必要であり、インデックス付けと走査において特別な扱いが必要となります。このような方法でグラフデータベースを調整することは理論上可能ですが、基盤となるグラフ表現とそれに対応するアルゴリズムの利点は明確ではありません。
さらに、MeTTAの中心となる操作は、変数の統一を伴うパターンマッチングです。この操作は、クエリと照合される知識ベースのエントリ双方に対して行われます。しかし、このような機能は既存のクエリエンジンではサポートされておらず、キーバリュー型ストアのような下位レベルのホスト表現では、より簡潔に実装できます。これが、RAMメモリ内蔵のAtomspaceや分散型アトムスペースの両方で、グラフストレージをバックエンドとして使用しない理由です。
Greg Meredithは、MeTTaの主要開発者であるAlexey Potapov、Vitaly Bogdanov、Adam Vandervorstと協力して、MeTTaの公式操作セマンティクスを作成しました。このセマンティクスはこちらで公開されています。また、公式のMeTTaコードリポジトリも存在しており、アイデアのプロトタイピングに使用され、それらがMeTTaのメインコードベースに移植される前にテストされています。
MeTTaとコンピュータサイエンスや形式論理学で用いられる型システムとの関係は、この概要レベルでも簡単に触れておく価値があります。MeTTaは本質的に非常に汎用性が高く、型を持ちません。これは、基本的にMeTTaがメタグラフ上の書き換え規則であり、その規則がメタグラフ自体に埋め込まれているためです。しかし、型は選択されたノードやリンクに付加されたメタグラフの一部に過ぎないため、その中で型システムを構築することができます。その結果、依存型、漸進型、確率を表す高階型など、非常に汎用性の高い型システムを構築できるようになります。ただし、このような複雑な型に対して効率的な型チェッカー(型検査器)を書くことは依然として課題であり、高度なコンピュータサイエンスの知識が求められます。
AGI-22OpenCogワークショップにおいて、Jonathan Warrellはこのプログラミングフレームワークの洗練さと汎用性を示す例として、MeTTaを用いてピーター・アクゼルの非有基的集合論の非常にコンパクトな実装を披露しました。この理論における集合は、自己を要素として含むことも、循環的な包含関係を持つこともできます。この実装では、Atomspace内に非有基的集合を表現するために循環グラフを活用し、それらを書き換えるためのルールを確立しました。これにより、無限次確率に基づく確率論のエレガントな実装が可能になります。これはゲーツェルが提案した、不確かな共有社会的知識の扱い方としての手段であり、「私たちはお互いに、この命題が多分正しいことを知っている」といった共有理解や、あらゆる「我と汝」関係と強固な文化を特徴づける、より有益なバリエーションの共有理解を扱う手段として役立ちます。
スティーブン・ウルフラムの理論物理学の観点から追求した「ルリアド」の概念と、MeTTaのAtomspaceとの間には、密接な関連があります。どちらも、パターンが無限に階層化された構造(再帰制限なし)を表現するメタグラフ構造であり、無限グルーポイドや(∞,1)-圏などの関連する数学的構造を使ってモデル化することができます。しかし、ウルフラムが物理学に触発された研究で特に興味を持っているルリアドの特定領域は、近い将来のAGI文脈で最も有用と考えられるメタグラフの種類とは異なります。
MeTTaという名前は、Meta-Type-Talkの頭字語ですが、ベン・ゲーツェルはAGI-23での講演の中で次のように述べています。仏教哲学における “metta” という言葉は、慈愛を意味することにも注目しています。印象論的には、この名前は、哲学的にもコンピュータサイエンス的にも、システムを善意あるAIへと導くものとして解釈できるでしょう。
3.1.1 もう一つのプログラミング言語の必要性
ベン・ゲーツェルは、AGI-23講演の中で次のように述べています。1990年代半ばに斬新なAGI言語の開発に初期段階で取り組んだ後、私は新たな言語の開発は、真面目なAGI研究者にとって魅力的な選択肢ではあるものの、避けるべき誘惑であるという結論に達しました。多くの研究者は、適切なプログラミング言語があればAGIの実装作業が容易になると考えていました。しかし、30年後、彼らはキャリアの大半がAGIではなく、プログラミング言語の研究開発に費やしていたことに気づくのです。それにもかかわらず、私はAGI研究キャリアの数十年の経験を経て、新しいプログラミング言語の作成に携わっています。しかし、LISPやPrologなどの過去の事例とは異なり、Hyperonチームでは、この新しい言語を開発するにあたって、実装したい具体的な機能が多数あるという点でアプローチが異なります。私たちはすでに他の言語やフレームワークでプロトタイプのAGIシステムを構築してきた経験があるため、AGIのアイデアを効果的に実現するために必要な言語の特性や要素をかなり明確に把握しています。
Alexey Potapovは、この点をさらに詳しく説明しています。代替案を慎重に検討した結果、知識表現、パターンマッチングクエリ、およびそれらを連鎖する機能を、専用の言語であるMeTTaに組み込むことにしました。MeTTaはHyperonの基盤となる基本コンポーネントです。知識表現の必要性は明白であり、認知言語の導入も認知アーキテクチャや類似のプラットフォームでは非常に一般的です。しかし、MeTTaを独立したプログラミング言語として開発すべきかどうかは、 長い間慎重に検討を重ねました。認知言語は制限されたり特殊化されたりすることが多く、汎用プログラミング言語内でのDSLやライブラリとして実装することもできます。
Hyperonは、複数のパラダイムを横断して研究を行うためのプラットフォームであるため、その認知言語があまりにも専門的であってはならないことは明らかでした。
Agdaなどの証明支援系言語、Prologなどの古典的な論理言語、ChurchやAnglicanなどの汎用確率プログラミング言語は、いずれも特定のパラダイムに特化しています。例えば、PrologにはProbLogのような拡張機能が存在しますが、それらは独立したプロジェクトであり、互換性がありません。同様に、確率プログラムの実行履歴を分析するには、言語インタプリタを直接操作する必要があります。これらの言語はネイティブに知識ベースと連携することができず、外部のグラフデータベースをクエリするだけで、認知アーキテクチャに必要な多くの機能を備えていません。
Hyperonを汎用ホスト言語のライブラリとして実装する際にも、いくつかの障害が存在します。まず、Hyperonには推論ルールや手続き知識を含む、すべての知識エントリが内省的で書き換え可能であるべきユースケースが存在します。例えば、PyTorchのようなPythonでHyperonをライブラリとして使用する場合、Atomspace内の知識としてプログラムされるHyperon言語で表現し、Pythonコードは必要最低限に抑えたいと考えられます。Pythonコードは、内省可能な知識ではなく、推論の対象にならないからです。従来の言語で実装された特製のシンボル系システムの例は多く存在しますが、そのようなシステムではシンボル情報の処理が命令型言語で行われており、相互互換性がなく、より大きなシンボル系システムで使用することができません。
そのため、推論ルールを認知言語自体で実装することは非常に重要です。これは、その言語がかなり汎用的で豊かである必要があることを意味します。ただし、これはその認知言語がPythonやRustのように汎用的であるべきだという意味ではなく、汎用言語とのインターフェースから多くの恩恵を受ける必要があるという意味です。つまり、この認知言語は様々なAIシステムやコンポーネントを実装するのに十分なものでなければなりません。Atomspaceに格納されると、これらのプログラムはホスト言語のコードとして表現されず、独自のインタプリタによって評価されます。この認知言語専用の構文を持たず、既存のホスト言語の構文を使用してAtomspaceを埋めることも可能ですが、ホスト言語の構文を抽象化し、純粋な認知言語のコードを分離することで、さらなる利点が生じます。
基本的に、HyperonはOpenCog Classicや他の多くの認知アーキテクチャと同様に、独自の内部認知言語を備えています。この言語は、Hyperonの設計全体が持つ普遍性と柔軟性によって、他の言語とは一線を画します。そのため、言語を持たないという選択肢は存在しません。そして、この言語をプログラミング言語として扱うか、ライブラリの作成、デバッグなどの機能を持たない「単なる」内部認知言語として扱うかは、利便性の問題となります。明らかに、HyperonのPLN、MOSES、ECANなどの各種コンポーネントや、カスタム推論戦略やDNNとの統合方法が異なるライブラリなどをMeTTaで実装したい場合、MeTTaをプログラミング言語として扱う方が便利です。
3.1.2 MeTTaの概要
MeTTaは革新的な言語であり、習得するには従来のプログラミングの考え方を捨て、新しいアプローチを身につける必要があります。そのため、簡単な概要だけでは十分な理解は得られないかもしれません。しかし、十分な技術的背景を持つ読者向けに、簡潔にMeTTaの特徴と他の言語との差別化ポイントをまとめることは、依然として価値があるように思われます。
MeTTaプログラムは、式の集合であり、これらはAtomspaceと呼ばれるコンテナに格納されます。式は、「アトム」と呼ばれる基本要素のタプル(集合:複数要素の組み合わせ)で構成されます。このアトムは、以下の3種類に分類できます。
- 別の式:より複雑な複合式を構築するために組み合わせられる部分式です。再帰的にネスト(入れ子)構造となっており、別の式自体を要素として含むことができます。これにより、階層的なデータ構造を表現することが可能になります。
- 純粋なシンボル:特定の概念や値を抽象的に表現するシンボルです。プログラム内で利用される変数名とは異なり、あらかじめ定義された意味を持ちます。例えば、「赤」や「3.14(円周率)」といったシンボルがこれに該当します。
- グラウンデッドアトム(接地アトム):MeTTaプログラム自体では完全に記述されない(部分記号的)サブシンボリックなデータをラップする特別なエンティティです。センサー値や画像の一部など、記号だけでは表現しきれない情報がこれに当たります。パーサーはこのようなグラウンデッドアトムに変換すべき値を認識し、適切に処理を行います。
例えば、以下のものは有効な式です。
- MySymbol:単純なシンボルです。プログラム内で特定の概念を表すために利用されます。
- (A (B C D) E):複合式で、タプル
(B C D)を含むアトムAとアトムEからなるタプルです。ネスト構造の例を示しています。 - (”point” (10 10)):グラウンデッドアトムを含む複合式で、文字列
"point"と数値のタプル(10 10)からなるタプルです。この式内の"point"と10は、パーサーによってグラウンデッドアトムに変換されます。パーサーはプログラムの構文を解析するソフトウェアで、この場合は"point"を座標を表すデータに変換する処理を行うと考えられます。
Atomspacesは他のコンテナとは異なり、式をそこから取得するための特別なクエリ機能を備えています。MeTTaの式はメタグラフのエッジとして扱われ、 Atomspaces全体はインデックス付きの内容を効率的に操作するクエリエンジンを備えたメタグラフのデータベースや知識ベースとして機能します。さらに、Atomspacesに対するクエリは、関数型言語のパターンマッチングを汎用化した概念としても理解できます。クエリは通常、特殊なタイプのアトム、つまり変数を含む式です。現在の構文では、記号の先頭に $ を付加することで変数は通常のシンボルと区別されます。変数を持つ式はパターンと呼ばれることがあります。
例えば、式 (A (B C D) A) は、以下のクエリ(パターンとの一致検索)によって検索できます。
- (A $x A):このパターンでは、
$xはワイルドカードとして機能し、式(A (B C D) A)内の任意の部分に一致することができます。 - (A (B $x $y) A):このパターンでは、
$xと$yはそれぞれ独立した変数であり、式(A (B C D) A)内の対応する位置(CとD)に一致しなければなりません。 - ($x (B C D) $x):このパターンでは、
$xは式(A (B C D) A)の最初と最後の複数部分のAに一致する値でなければなりません。
しかし、(A ($x $y C) A)、(A (B C D) (A $x))、($x ($x C D) A) のクエリは、式 (A (B C D) A) には一致しません。
Atomspacesは、他の多くのデータベースコンテナと異なり、変数を含む式を格納できる特徴があります。式内でクエリと変数が互いに矛盾なく部分式にバインドできた場合、それらの式とクエリがマッチングされます。バインドとは、変数に具体的な値を割り当てる操作を指します。例えば、式 (A ($a $a) A) は、クエリ ($b (B B) $b) と一致しますが、クエリ ($b (B B) C) や ($b (B $b) $b) とは一致しません。後者の場合、両方の変数 $a と $b に対して、2つの式を完全に一致させるような置換を見つけることができないからです。
コアとなるパターンマッチング関数は、「クエリパターン」と「結果パターン」の2つのパラメータを受け取ります。指定されたAtomspace内でクエリパターンと「統一」可能な式を検索し、統一によって得られた値を用いて、結果パターン内の変数を置換して結果を出力します。統一とは、変数を含む2つの式が同じ意味になるように、変数に具体的な値を割り当てるプロセスを指します。例えば、クエリパターンが (A (B $x $y) A) であり、結果パターンが (Found $x $y) の場合、このクエリパターンが (A (B C D) A) と一致すると、結果は (Found C D) になります。
一部のグラウンデッドアトムは、ホスト言語で実行可能なコードをカプセル化することができます。MeTTaの式は評価対象であり、もし式が実行可能なグラウンデッドアトムで始まる場合、その式の評価はラップされたコードの実行を引き起こします。具体的には、match はパターンマッチングの実装を指すグラウンデッドアトムであり、&self はMeTTaプログラム自体が格納されているAtomspaceを参照するグラウンデッドアトムです。例えば、 MeTTaの式として (match &self $(A (B $x $y) A) (Found $x $y)) を評価すると、プログラムのAtomspaceに対して対応するクエリパターンと結果パターンを用いたパターンマッチングが実行されます。
MeTTaスクリプトが処理されると、その式はプログラムのAtomspaceに格納されます。もし特定の式をすぐに評価したい場合は、現時点では式の前頭に ! を付ける必要があります。以下のMeTTaプログラムの実行過程を見てみましょう。
(Sam is a frog)
(Tom is a cat)
(Sophia is a robot)
! (match &self ($x is a robot) (I know $x the robot))
このプログラムでは、最初の3つの式はプログラムのAtomspaceに格納されます。そして、最後の式の評価によって (I know Sophia the robot) が生成されます。
プログラムのAtomspaceに格納されたパターンは、汎用的な知識を表すのに役立ちます。以下に、その例を紹介します。
(Implies (Human $x) (Mortal $x)) ; すべての人間は死ぬ (含意関係)
! (match &self (Implies (Human Socrates) $y) (Concluding $y)) ; (即時評価)
このプログラムを実行すると、(Concluding (Mortal Socrates)) を出力します。なぜなら、変数 $x を Socrates に、変数 $y を (Mortal Socrates) に置き換えると、クエリはAtomspaceの式と統一できるからです。このプログラムは、ソクラテスが人間であるという知識と、人間なら誰でも死ぬという含意関係を使って、ソクラテスは死ぬことを推論します。
グラウンデッドアトムの評価は、それらをラップする実行コードに委譲されますが、シンボル式の評価は、等式クエリを構築するインタプリタによって行われます。つまり、式 $(f a) を評価する場合、クエリ (match &self (= (f a) \$r) \$r) が構築され、このクエリの結果がさらに評価されます。もし等式クエリの結果が空(マッチなし)であれば、その式は簡約化されずに、そのまま自分自身に評価されます。では、以下のプログラムを見てみましょう。
(= (add (S $x) $y) (Add $x (S $y))) ; (add (S $x) $y) は (Add $x (S $y)) と等しいか?
(= (add Z $x) $x) ; (add Z $x) は $x に等しいか?
! (add (S Z) (S Z)) ; (add (S Z) (S Z)) を評価する (即時評価)
この節では、式 (add (S Z) (S Z)) の評価過程を通して、MeTTaのシンボル式評価の仕組みについて説明します。
- 初期クエリパターン:まず、MeTTaは評価対象の式
(add (S Z) (S Z))と一致するかどうかを調べるために、クエリパターン(= (add (S Z) (S Z)) $r)を生成します。この$rは、後続の評価のために導入された変数です。 - 最初の式との統一:このクエリパターンは、MeTTaが保持するAtomspace内の知識である最初の式
(= (add (S $x) $y) (Add $x (S $y)))と統一できます。この統一により、変数$xにはZが、$yには(S Z)が、$rには(add Z (S (S Z)))がバインディングされます。 - 再帰的評価:
$rにバインディングされた(add Z (S (S Z)))はまだ評価されていないため、新たなクエリパターン(= (add Z (S (S Z))) $r)が生成され、評価が繰り返されます。 - 2番目の式との一致:このクエリパターンは、Atomspace内の2番目の式
(= (add Z $x) $x)とも統一でき、変数$xには(S (S Z))がバインディングされます。 - 評価の終了:さらに評価を進めますが、
$rの値$xを使って一致するパターンが見つからないため、空の結果が返されます。 - 最終結果:空の結果が得られたため、
$rの値(S (S Z))がそのまま評価され(簡約化されず)、最終結果となります。
MeTTa式の評価は、等式クエリチェーンを用いることで実現されており、これは関数型プログラミングにおける関数呼び出しのパラダイムと機能的に類似しています。しかし、これらの等式は単なる計算結果ではなく、知識ベースに永続的に格納されたエントリとして依然として存在し、明示的にクエリが可能である点に留意する必要があります。例えば、先ほどのプログラムに対して、以下のクエリを実行してみましょう。
(match &self (= (add $x $y) Z) (Answer $x $y))
このクエリは (Answer Z Z) を返します。なぜなら、このクエリのバターンは、プログラム内の (= (add Z $x) $x) とのみ一致するからです。注意:同一のパターン内で同じ名前の変数は、別々の変数として扱われます。
変数を含むクエリは、データベースクエリに似ています。一方、変数を含むプログラムの式は、関数型プログラミングに似ています。両方の式に変数を持つことで、論理プログラミングに似た機能が可能になり、関数型プログラミングと知識ベースが統合された形で実現されます。以下の例では、標準ライブラリの True と and を用いて、カエルに関する知識を表現し、推論を行います。
(= (croaks Fritz) True) ; カエルのフリッツは鳴く
(= (eat_flies Fritz) True) ; カエルのフリッツはハエを食べる
(= (frog $x) (and (croaks $x) (eat_flies $x))) ; カエル(x)は鳴き、ハエを食べる
(= (green $x) (frog $x)) ; 緑色(x)はカエル(x)である
! (green Fritz) ; (即時評価) フリッツは緑色?
最後の式 ! (green Fritz) は、関数型プログラミングと似た方法で True に評価されます。特筆すべきは、(green Sam) が単に False を返さず、(and (croaks Sam) (eat_flies Sam)) に簡約される点です。さらに興味深いのは、(if (green $x) $x (no-answer)) という式も Fritz を返して評価できる点です。MeTTaが変数を含む式を評価できる理由は、等式クエリを構築するためです。例えば、(green $x) は、クエリパターン (= (green $x) $result) を介して評価されます。このクエリでは、$result が (frog $x) にバインディングされます。そして (frog $x) はさらに (and (croaks $x) (eat_flies $x)) に評価されます。その後、クエリパターン (= (croaks $x) $result) はプログラム内の (= (croaks Fritz) True) と一致し、$result が True に、$x が Fritz にバインディングされます。
MeTTaでは、自動的な等式に基づく連鎖を回避したい場合、プログラマーは match を使用して純粋に宣言的な知識に対する独自の推論ルールを定義することができます。例えば、クエリパターンにおけるカンマ (,) は、2つのサブパターンを同時に満たすエントリを知識ベースから検索することを意味します。サブパターンは異なる式であっても、変数バインディングは共通となります。以下のプログラムを見てみましょう。
(Fact (Human Plato)) ; プラトンは人間である (事実)
(Implies (Human $x) (Mortal $x)) ; 人間なら誰でも死ぬ (含意)
! (match &self (, (Implies $a $b) (Fact $a)) (Inferred $b))
上記の例では、人間が死ぬという含意(Implies)関係とプラトンが人間であるという事実(Fact)から、プラトンは死ぬという結論を導き出します。このプログラムを実行すると、(Inferred (Mortal Plato)) が出力されます。
MeTTaにはいくつかの特定の機能があります。
1. 非決定性:クエリは複数の結果を返すことができ、等式に基づく評価も複数の結果を返すことができます。例えば、 (match &self (is-a $x Human) $x) は、 &self 内に (is-a Plato Human) と (is-a Socrates Human) が含まれている場合、プラトンとソクラテスの両方を返します。
2. 漸進的依存型:MeTTaでは、シンボルに型を割り当てることができ、式の型はパターンマッチングを含め、自動的に推論されます。漸進的依存型は、型の推論が式の評価過程とともに徐々に進められることを意味します。以下の例は、MeTTaの型システムの表現力を示しています。
(: Nat Type) ; 自然数型
(: Z Nat) ; ゼロを表す型
(: S (-> Nat Nat)) ; 後者関数型 (自然数 -> 自然数)
(: Vec (-> $t Nat Type)) ; 長さを持つベクトル型 ($tは任意の型)
(: Cons (-> $t (Vec $t $x) (Vec $t (S $x)))) ; Cons コンストラクタ型 (要素の型 $t, 先頭の要素 $x, 末尾のリスト)
(: Nil (Vec $t Z)) ; 空リスト型 (要素の型 $t)
上記の定義を使って式 (Cons 0 (Cons 1 Nil)) の型を推論すると、(Vec Number (S (S Z))) になります。これは、2つの要素を持つ自然数ベクトルの型を表します。
3. カスタムグラウンデッドアトム: MeTTaプログラムは、別の言語(Rust, C++, Python)で記述されたカスタム外部データ構造やコードをラップするグラウンデッドアトムによって拡張できます。これは、根拠推論やNeural-symbolic統合において重要な機能です。
4. 自己修正:match のほかに、AtomspaceAPIにはアトムの追加や削除の関数が含まれており、これらはMeTTa内でグラウンデッドアトムとして表現されます。したがって、MeTTaのプログラムは自身のコードを完全に書き換えることができます。
3.1.3 AGIのためのMeTTaインタプリタの最適化
MeTTaという言語は、AGI以外にも幅広い用途に活用できる言語です。論理プログラミングと関数型プログラミングの両方を柔軟に扱い、実行時に生成される型システムを含む様々な型システムをホストできるという機能は、多くの異なる分野で複雑なプログラミング作業を簡素化できます。しかし、MeTTa開発における我々の主要な目標はあくまでAGIの実現です。そのため、最も重要と考えられるAGIアルゴリズム群に対して効果的なパフォーマンスを発揮するように、MeTTaインタプリタを最適化する方法について綿密な分析を重ねてきました。
ベン・ゲーツェルは次のように述べています。2020年、COVID-19パンデミックの影響で出張が激減し、例年以上に理論的な研究に時間を割くことができました。この機会に、数年前に中断していた数学的なAGI理論の研究を再考し、OpenCogアプローチに基づくAGIに必要なすべてのアルゴリズムは、メタグラフ上で「折り畳み」と「展開」と呼ばれる操作の高度なバージョンによって、かなりの精度で表現できるのではないかという仮説を検証しました。
特に、関数型プログラミング理論には「モルフィズム動物園」と呼ばれる一群の操作(futurism、histomorphism、metamorphismなど) が存在します。通常、これらの操作はリストやツリー構造上で実装されますが、私にとっては、これらの「再帰スキーム」をメタグラフ上で実装することで、論理推論、進化学習、注意配分などの効率的な実装基盤を構築できるのではないかと思いました。これらはすべて、人間のような心を再現する上で不可欠だと感じていた中核的な技術です。
MeTTaインタプリタがメタグラフ上での折り畳みと展開の操作を効率的に実行できれば、HyperonシステムにおけるAGIアルゴリズムの効率化が大幅に進むと考えられます。つまり、多様なAGIアルゴリズムの背後にある共通構造と操作を明らかにするために、数学的なアプローチを取ることに価値があります。この数学自体は、最新の数学の中でも最も複雑なものとは言えませんが、20年前には実現が難しかったものです。当時は、関数型プログラミングの数学がまだ完全には発展しておらず、このような進展が可能ではありませんでした。
このアプローチの欠点としては、典型的なコンピュータプログラマーが扱うにはやや抽象的すぎることです。もちろん、アプリケーション開発者や認知科学者にとっても同様です。しかし、コンピュータや携帯電話の利用者が、その基盤となっている半導体物理学を理解する必要がないのも事実です。システム設計における課題は、洗練された基盤となる仕組みを利用できるようにしつつ、すべての詳細を理解する必要のない、ドメイン固有言語、API、その他の簡略化されたツールを作成することです。
3.1.4 MeTTa開発の次の段階における課題
MeTTaは既存のプログラミング言語とは大きく異なり、その最も近い親戚と言われている言語も、筋金入りの関数型プログラミング愛好家しか知らないような比較的マイナーな言語です。MeTTaが実際にどのように動作するのかを本当に理解したい方には、Alexey Potapovによるチュートリアル動画 [1] [2] が良い出発点になるでしょう。また、MeTTAプロジェクトの開始当初に書かれたAlexeyの基本概念のドキュメントも参照することをお勧めします。より数学的な観点からMeTTaを理解したい方には、Greg MeredithによるMeTTaの操作セマンティクスの解説が参考になるでしょう。
MeTTaの開発は多くの作業を経て現在の段階に到達しましたが、この言語はすでにいくつかのAGI志向のアルゴリズムの実験に利用されています。しかし、人間レベル(およびそれを超える)のAGIの開発と再帰的自己プログラミングを可能にする基盤言語として効果的に機能させるためには、MeTTaをさらに進化させる必要があります。MeTTaに関する詳細資料をご覧になった方は、Adam VanderVorstによるMeTTa開発の次の段階における課題に関するコメントにも興味を持たれるでしょう。AdamのFormal Mettaコードベースも興味深く、純粋な数学的観点とMeTTaの主要なRustコードベースとの橋渡しとして非常に役立っています。
Adamは、MeTTaの現状と未来について次のようにまとめています。Hyperonエコシステムの中核を担うのが、Atomspaceと呼ばれる空間です。これはOpenCog Atomspaceの後継にあたるもので、新たに開発されたMeTTa言語(こちらもAtomese言語の後継者)をサポートするために、ゼロから構築されました。AtomspaceとMeTTa言語は、どちらも根本的に簡素化されており、ファーストクラスラムダ式やクオートは使用されず、型システムは項と同じレベルで扱われます。また、手動でのクエリ作成は、統一された(入れ子構造の)統一構文に置き換えられ、カスタム機能の追加も容易に行えるようになっています。これらの簡素化により、本ドキュメントで紹介した多くの進歩が可能になりましたが、その一方で新たな課題も生じています。以下では、そうした課題について詳しく説明していきます。
1. シンプルな項言語:MeTTaの基本的な項言語は、非常に強力で柔軟性を備えています。しかし、より広範囲の開発者グループが実際に利用できるようにするには、ドキュメントとツールの拡充が不可欠です。MeTTaのコアとなる型は、基本的に4種類しか存在しません。
- シンボル(名前):基本的な用語や概念を表します。
- 変数(プレースホルダー):具体的な値が入る枠のようなもので、計算や推論の中で値が代入されます。
- グラウンデッドシンボル(カスタム機能):ユーザーが定義した処理や機能を表します。
- 式(上記の基本型のリスト):シンボル、変数、グラウンデッドシンボルを組み合わせて、論理的な関係や計算を表します。
このため、代数的データ型のような複雑なデータ構造は、他のあらゆる構成要素と同じように宣言して使用する必要があります。関数についても同様で、変数を統一できるスコープに分割してから、変数を含む通常の式として記述する必要があります。それでは、より具体的に見てみましょう。
(= (succ \$x) (S \$x))
一見、この定義はそれほど悪く見えません。この式で使われているシンボルはどれもグラウンデッドではなく、変数は $x だけですし、残りはシンボルです。しかし、この式のいくつかを名前変更すると、次のような式に変換されてしまいます。
(If (Has $money) (make $money))
このようになると、本来の式の意図が完全に失われてしまいます。汎用性には両刃の剣があり、MeTTaでは new キーワードによるクラスのインスタンス化や def キーワードによる関数定義といった専用構文を持たないことで、極めて高い柔軟性を獲得しています。さらに、名前変更(それ自体が等式である)のようなステートメントも実行時に追加できるため、その柔軟性はさらに高まります。
しかし、わかりやすく安全な言語を作るという希望は完全に失われたわけではありません。近年では、「名前付け」と「機能定義」を分離する言語がいくつか登場しています。Unisonはその一例で、コードをデータベースに格納し、正規化されたコード断片に名前を付ける別のファイルを保持しています。Lamduも注目すべき言語です。彼らは名前付けの柔軟性を利用して、かつてないレベルの国際化を実現しています。インタラクティブなエディタにより、ユーザーは仮想インライン展開、ライブ評価、ホバー時のエイリアス表示といった機能によって、どの名前が何にバインドされているのかを容易に確認できます。MeTTaのような低レベルで表現力豊かな動的な言語の成功には、ツールが極めて重要になります。
この例では、いくつかの点で慣習を破っている点に注意してください。
- シンボル「=」のエイリアシング(別名)は、マッチングと評価を通して直接インタプリタに渡されます。
- 関数「succ」は、プロパティやデストラクタのような見た目を持つ「Has」という名前でエイリアシングされています。
- コンストラクタ「S」は、関数のように見える「make」という名前でエイリアシングされています。
エディタ上では、関数は評価に組み込まれる記号の種類に関係なく、関数として表示できます。新しく定義された名前は、プログラミング言語で慣例となっているようにハイライト表示されます。さらに、参照はエディタによって解決され、シンボルがその空間で定義されているかどうかを示すことができます。
しかし、これらの解決策はすべて、そもそも課題の原因となっている動的データベースの性質を利用しています。そのため、ライブラリやエディタの開発者は、MeTTaステートメント内のシンボルの意味をMeTTa自体で定義する必要があります。これにより、ユーザーやそのツールがクエリを実行できるようになりますが、これは非常にメタな解決策であり、開発者に追加の負担がかかります。
2. 拡張可能な型システム:MeTTaのベース言語には型がありませんが、その上に複雑な型システムを構築することができます。これは、MeTTaの主要な利用形態になると考えられています。ただし、ベース言語が型を持たないという特性には、長所と短所があります。
MeTTaがサポートする統一と変換は、型チェック、型推論、および型の詳細化を実装するのに十分です。しかし、MeTTaプログラムは一度に全体を完成させるのではなく、時間をかけて構築していくものであり、理想的にはプログラム全体を一度に投入して型エラー報告を受け取るのではなく、型チェッカーと対話しながら進めることが望まれます。
MeTTaでは、型も単なる項として扱われます。例えば、(: succ (-> Nat Nat)) のように、プログラムを構築していく過程で、有効な項を徐々に絞り込んでいくことができます。
メリットとしては、型を先に定義するか項を先に定義するかを自由に選択して実験できる点が挙げられます。また、エディタを使用すれば、型推論エンジンが推測した型をコードベースに挿入することも可能です。デメリットとしては、プログラムの完成度を常に頭の中で把握しておく必要があることです。つまり、対話型のプロセスでは、欠けている定義があってもすぐにはエラーにならず、実行可能な部分までプログラムが実行されてしまいます。そのため、プログラムの計画と未完成部分のマーキングは、開発者とツールが共同で責任を負うことになります。これは、証明系における ??? のような穴埋め作業と似ており、型詳細化エンジンが穴埋めを助けてくれるイメージです。
3. シンプルで表現力豊かな簡約セマンティクス:コンピュータ科学者、関数型プログラマー、あるいはラムダ計算に基づく言語に慣れ親しんだAI開発者にとって、MeTTaに明示的なラムダ式メカニズムが欠如していることは、直感的に理解しにくいと感じるかもしれません。
MeTTaでは、古典的なベータ簡約(変数置換)ではなく、統一と呼ばれるメカニズムを用います。この双方向置換メカニズムは、Epic Gamesが開発した新しいプログラミング言語Verseとその計算体系でも採用されており、情報の伝達が双方向に行われるという特徴があります。具体的には、結果を式から計算できるだけでなく、式を結果から計算することも可能で、さらにその組み合わせも自由に行えます。この機能は、関数論理プログラミング以外のプログラミングパラダイムに慣れたユーザーにとっては、かなり違和感を感じるかもしれませんが、局所的な宣言型ステートメントを用いることで、数学的に期待される動作を実現することができます。
しかし、統一は強力な手法ですが、多くの場合においては必要ありません。MeTTaで常に「予期せぬ結果」が生じる可能性があるため、潜在的な意味について慎重に検討する必要があります。この課題は、名前のエイリアシング(前述)やグラウンディング(後述)と同様のアプローチで対処できます。具体的には、MeTTaステートメントなどの追加の情報によって、ユーザーと最適化ツールに制御フローを提示することができます。
4. matchによる空間の変換: 前述のとおり、MeTTaにはあらゆる種類のクエリに対応する統一された構造があります。この match 構文は、最も簡単な検索(例:センサー[温度][外部])から始まり、二段階の変換(古典的な異なるフィールドの結合とミートを連鎖させた挿入のオーケストレーション)まで幅広い用途に使用できます。 以下に具体例を示します。
単純な検索:この構文は、センサーデータの中から、屋外温度 $t を表す値を問い合わせるものです。
sensors[temperature][outside]:
(match &sensors (Temperature Outside $t) $t)
2段階の変換:この構文は、より複雑な処理を表しており、2段階の match をネストさせています。
(match &process (send $channel, $payload)
(match &process (recv $payload $channel $body)
(Result $body)))
ここで注意すべき点は、追加のJITコンパイルステップなしでは、1回目のデータベースクエリ結果に対して毎回クエリが実行されることです。このような最適化問題は、多値入力に対する関数にも同様に適用されますが、以前から多くのグループによって取り組まれてきました。しかし、MeTTaでは統一という要素がさらなる複雑さを加えています。
5. カスタム関数:Atomspaceの外部で実装された他言語関数を参照する「グラウンデッドアトム」は、極めて重要かつ価値の高い機能であり、柔軟な利用が可能です。しかし、開発者にとっては複雑な選択を伴う要素にもなります。「このアトムはグラウンデッド化されているか?」「グラウンデッド化すべきか?」という問題には、必ずしも明確な答えがあるわけではありません。
浮動小数点のような基本的な機能からPyTorchモデル全体まで、4つのコア型以外の機能はすべてグラウンディング(接地)と呼ばれる仕組みで追加されます。グラウンディングは、値、パターンマッチングの動作、および評価を変更することができます。しかし、これはMeTTaと呼ばれるシステムの外部で行われるため、グラウンディングされた定義は通常の定義のようにクエリで参照することができません。そのため、ライブラリ作成者は、グラウンディングされた定義の詳細な説明を追加する責任が伴います。例えば、MeTTa内の定義であれば、関数が取る引数の数を調べるクエリを実行できますが、グラウンディングされた関数の場合には、この情報をメタスペースと呼ばれる情報空間に追加するか、またはスタブと呼ばれる代替実装を使用する必要があります。
依存関係はさらに複雑な問題です。match クエリや評価全般は、特定のシンボルを考慮に入れます。例えば、= はグラウンデッドシンボルではありませんが、グラウンデッド関数内で使用されています。もし match がMeTTa内部で実装されていれば、定義を解析して = のエイリアシングについて通知する関数を書いたり、自分でそれに対するグラウンディングを書いたりできます。例えば、ある開発者がカンマ , をペアを表すシンボルとして使用していたにもかかわらず、ある時点で match のグラウンディングが変更され、このシンボルに複合クエリを示す特別な意味が割り当てられたために、開発者のコードが破損してしまったという事例があります。
MeTTaにおける依存関係の管理には、いくつかの潜在的な解決策が考えられます。具体的には、名前空間、コードサニタイザー、インタプリンタ警告などがあります。包括的な解決策を導き出すには多大な労力が必要であり、MeTTaを大規模なコードベースや長い依存関係チェーンに対応させるために必要とされています。
3.2 LLM時代におけるHyperonの立ち位置
この文書の後半部分からもわかるように、MeTTaやHyperonの他の側面には、それ自体にかなりの技術的深みがあります。これらは、それぞれ長い歴史を持つ学術的および実用的な知識体系や伝統に依拠しています。一方で、現代のAI分野は、LLMによって大きく支配されており、これらの技術はMeTTaのような高度で繊細かつ複雑なアプローチとは全く異なる方向から発展してきました。そのため、HyperonがLLMのランドスケープの中でどのように位置づけられるのかを考察することは自然な流れです。「LLMの欠点を克服すること」という考え方は、Hyperonの開発当初からの動機でも、Hyperonを考える上で最も自然な方法でもありません。しかし、特にLLMをHyperonと様々な方法で統合する実践的なシステムを構築する文脈では、思考実験的にこの角度から考えることには意味があります。
LLMは、汎用知能の文脈で興味深い位置を占めています。LLMは、原理的にはNarrow AIに分類されますが、人間の感覚では非常に広範な範囲を扱うことができます。LLMは膨大な訓練データを利用して動作しますが、それを超えた汎用化は限られています。LLMが訓練データを大きく超えて進化しないという事実は、本質的に初期のプログラムや訓練データを超えて汎用化する強力なAGIとは、この点が大きく異なります。しかし、LLMは膨大な訓練データをわずかに超出する汎用化能力を持つことで、非常に幅広いタスクを実行できます。なぜなら、その訓練データは人間の日々の活動における関心事の多くをカバーしているからです。
また、LLMがある種の「創発」現象を示していることも注目に値します。創発とは、個々の要素の単純な相互作用から、システム全体として新しい性質が生まれる現象のことです。例えば、LLMはネットワークの重みを変更せずに、ニューラルネットワークの活性化空間内でのダイナミクスのみで新しい事例に適応し、Few-shot Learning(少量の学習データによる学習)とIn-context Learning(文脈に依存した学習)を実現しています。ニューラルネットワークで重みを変更せずに学習するという概念自体は新しいものではありませんが、LLMがこのタイプの学習を適用できる規模は前例のないものです。
一方で、LLMにはいくつかの深刻な限界もあります。具体的には、科学研究や画期的な数学定理の生成に必要な体系的な多段階推論は、これらのシステムにとって困難です。これは、LLMが既存の知識に依存しがちで、それを大きく超えて拡張することができないことが一因です。さらに、 LLMは創造性に欠けており、芸術的に革新的な作品を生み出すことは言うまでもなく、美的に豊かだったり感動させたりするような作品を生み出すこともできません。結局のところ、LLMの大きな限界は、その狭さ、つまり訓練データに依存した特性に密接に関連しています。
AI研究コミュニティ全体では、LLMとAGIの関係性について意見は大きく分かれています。例えば、ゲイリー・マーカスとヤン・ルカンは、LLMをAGIへの遠回りだと考えています。一方、LLMを大きな進歩と捉える研究者も多く、現在のLLMを拡張して強化するか、他の技術と組み合わせたりすることで、人間レベルのAGIを達成できると考えています。
この文書を読み進めるにつれてさらに明らかになりますが、LLMはHyperonシステムやそれに関連する理論の中核とはほど遠い存在です。しかし、現時点の仮説としては、LLMがHyperonシステムと密接に、あるいは緩やかに統合することで、Hyperonベースの汎用知能において重要な役割を果たす可能性があります。
LLMから得られる教訓は、Hyperonやその他のLLMを中心としないAGI開発にも広く応用できます。例えば、驚くべきことかもしれませんが、LLMが強く示唆するのは、大規模なスケーリングがAIシステムの能力を飛躍的に向上させる可能性があるということです!Hyperonは、最新の深層学習フレームワークと同様に、より緻密な設計で、スケーラビリティを意識して構築されています。これを実現するために、最新のハードウェア、分散処理、さらにはブロックチェーンさえも活用しています。LLMの優れたスケーラビリティは、他のAIアルゴリズムも同様のスケーラビリティを実現するために、最新のコンピューティングとデータインフラ技術を活用する必要性を示唆しています。こうした取り組みにより、LLMが深層ニューラルネットワークの能力を向上させたように、他のAIアルゴリズムも本来の力を発揮し始め、LLMと効果的にハイブリッド化して、新たな形態の知能を生み出すことが可能になります。
もう少し掘り下げると、Alexey Potapovは、HyperonをLLMの代替または補完として追求する理由を以下のように説明しています。LLMは印象的な強みと同時に、その限界も一般的に認知されるようになってきました。既存の事前学習済みのLLMにシンボリック知識と推論を統合することで、短期的な成果は得られます。ただし、既存のLLMを(特にプロンプトを介して)先進的な知識グラフやシンボリック推論システムと統合するだけでは、人間レベルのAGIを達成するには不十分であると考えられます。
AGI研究開発における焦点は様々です。Hyperonの開発の文脈では、シンボリック要素を持つLLMの強化に、メタグラフクエリに基づく外部書き換え可能なメモリによるLLMの拡張などが考えられます。あるいは、LLM規模の大規模なDNNであっても、反射、本能、スキルのような特化モジュール(単独ではAGIやNarrow AGIではなく、広義のNarrow AI)と見なすことができます。これらのモジュールは、明示的な知識と推論エンジンによって統合され、他の手法や技術と組み合わせて制御されます。後者のアプローチにおいては、Hyperonの活用は極めて有効と考えられますが、同時に大きな課題も存在します。
AGI開発のあらゆるシナリオでは、現実世界の状況に対処する能力の獲得が求められます。現実世界の状況は、自然言語による記述よりもはるかに複雑で多様な情報を含んでいます。Hyperonベースのアプローチでは、そのような状況の明示的な表現を学習することを想定しています。この表現は、脆く壊れやすい従来の記号表現ではなく、 ニューラルネットワークが学習する暗黙的な表現よりもはるかに構造化されたものでなければなりません。これらのことから、Hyperonには克服すべき2つの主要な課題が存在します。
- 知識メタグラフのスケーリング:少なくともLLMが処理する情報量と同程度までの知識メタグラフをスケーリングする必要があります。
- シンボリックAIの脆さの軽減:シンボリックAI手法で時折見られる脆さを軽減する必要があります。この脆さは、手作業で作られた表現、ルール、アルゴリズムに依存することによって生じる傾向があります。
これらの課題を克服することは、異なるアプローチ、特にDNN/LLMの役割分担とNeural-Symbolic統合の形態の多様化によって実現できる可能性があります。しかしながら、最適なアプローチを選択すること自体が新たな課題となります。
3.3 特殊な空間と多様な役割
HyperonアプローチにおけるAGI開発の技術解説に戻ります。Hyperonには、中核を担うメタ表現ハブであるAtomspaceメタグラフに加え、標準のRAMメモリ内蔵のAtomspaceを補完するSpace APIも備えています。このAPIを介して、分散パターン記憶と検索、効率的な並行実行、ニューラルネットワークのアトムとしてのシームレスな統合など、様々な機能を実現する特化型スペースの構築が可能となります。
HyperonとMeTTaが持つ多様な空間こそが、単なる理論的な枠組みや研究ツールを超え、実世界のアプリケーションにおけるインフラとなる鍵となります。この柔軟性により、自己修正型コードスープ(コードの集合体)の作成から、ブロックチェーンにおけるスマートコントラクト言語の利用まで、幅広い用途への適用が可能になります。さらに、RAM容量の増加や高速プロセッサの登場など、コンピュータハードウェアの進歩により、MeTTaをより多くのアプリケーションに適用できる可能性が高まっています。
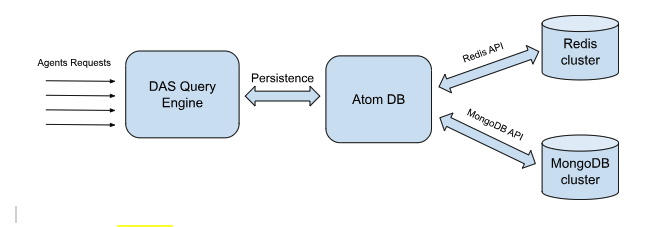
例えば、分散型アトムスペース(DAS)が存在します。これは、複数のマシンにまたがって実行できるAtomspaceの亜種です。DASは、現代的なNoSQLデータベース技術であるMongoDBとRedisを基盤としており、複数のマシンに分散した大規模な分散型アトムスペースを実現します。
また、Rholang(ローラン)Atomspaceと呼ばれるものもあります。これは、MeTTaプログラムをRholangにコンパイルしたものです。Rholangは、マルチコアマシンやマルチスレッド機能を備えたコアなど、並行処理インフラ上で各種プログラムを効率的に実行することで知られる言語です。現在、GSIが開発した最先端のAPU(Associative-Processing-Unity)チップ上でRholangを用いた実験が進行しています。「Rholang Atomspace」を作成することで、MeTTaプログラムをRholangにコンパイルし、それを並行処理インフラ上で効率的に実行させることができます。これにより、効率的な並列処理、ブロックチェーン技術との統合、暗号化などの機能がもたらされます。
複数の種類の空間を選択できるという機能は、もう一つの重要な利点をもたらします。それは、Atomspace APIを介してニューラルネットワークと連携する能力です。つまり、大規模言語モデルやその他の深層ニューラルネットワークをAtomspace APIでラップし、それらに対してパターンマッチングを実行することができます。これにより、形式的なパターンマッチングクエリと自然言語クエリやニューラルネットワーク内の活性化との間の変換を行う橋渡し機能が構築されます。この結果、Hyperonシステム全体におけるニューラルローブ(神経葉)としての役割を果たす「ニューラルアトムスペース」が形成されます。一つのHyperonインスタンスには、異なる目的のために特化した様々なニューラルアーキテクチャを実装した複数のニューラルローブを持つことができ、これらのニューラルローブは直接相互接続したり、デフォルトのAtomspaceなどの他の空間をハブとして利用することができます。
さらなる効率化とスケーラビリティの向上を目指した取り組みとして、専用のカスタムハードウェアと連携する試みがあります。それが、現在開発初期段階にあるOpenCogのパターンマッチングチップです。SimuliとTrueAGIのコラボレーションにより開発が進められているこのチップは、潜在的にハードウェアの制約上APIに制限はあるものの、HyperonスタイルのパターンマッチングをサポートするオンチップAtomspaceを搭載するように設計されています。
3.3.1 分散型アトムスペース
Andre Luiz de Sennaは、OpenCogに先立つWebmind認知エンジンとNovamente認知エンジンの主要開発者の一人であり、初期のOpenCog Atomspaceのオリジナルバージョンも開発しました。最近では、Hyperonの分散型アトムスペースの設計と開発を主導しています。(図2で簡略に描かれています) 彼はこの作業について次のようにまとめています。
分散型アトムスペース(DAS)は、OpenCog Hyperonが知識を表象および格納するために使用するハイパーグラフです。DASに格納されるべき知識の性質と量は、扱う領域や問題解決に使用されるAIアルゴリズムによって大きく異なりますが、AIエージェントは常にDASを知識源として、実行中に生成または達成された計算結果を格納するコンテナとして利用します。
DASは、データ構造としてあらゆるAIエージェントにおいて中核的な役割を果たします。AIエージェントの実行中には、常にハイパーグラフの走査、ノードやリンクのプロパティの照会、サブグラフのマッチングといった操作が実行されます。さらに、エージェントが学習を進める過程で、ノード、リンク、サブグラフの新しい要素の追加、プロパティの変更、接続性の変更といった要求も発生します。これらの要件を満たすために、DASはハイパーグラフ要素に対する効率的なCRUD(作成、読み取り、更新、削除)操作を備えた非常に柔軟なAPIと、プロパティ、接続性、サブグラフのトポロジーなどを含む複雑なクエリを効率的に実行するための堅牢なインデックスシステムを備えている必要があります。
大規模な知識ベースを扱う場合、このような柔軟で高速なAPIを維持することは大きな課題となります。そのためには永続的なバックエンドが必要になります。スケーラブルなデータベースエンジンを使用することは一見シンプルなアプローチですが、DASが要求するような方法で知識ベースを表現や格納するためには、解決すべき問題がいくつか存在します。
最初に取り組む課題は、どのデータベースエンジンを使用するかという選択の問題です。これは、Atomspaceの要素の中には、あるタイプのデータベースの方が表現しやすく、他の要素は別のタイプのデータベースの方が表現しやすいというように、適したデータベースが分かれていることが問題になるからです。クエリに必要なインデックスにも同様のことが言えます。各データベースエンジンは、ハッシュテーブル、正規表現に対応したテキストインデックス、地理空間インデックス、B木、スキーマインデックスなど、非常に便利な特殊なインデックスタイプを提供していますが、すべてのデータベースエンジンがこれらすべてを備えているわけではありません。
こちらに加えて、AIエージェントは特定の時点において、知識ベースの中で最も関連性の高い部分に集中し、ハイパーグラフの一部に焦点を当てながら他の部分を無視する能力が求められます。そのため、DASには階層的なキャッシュメカニズムが必要です。これは、最も関連性の高い情報をエージェントに近い場所(ローカルRAMメモリ)に保持し、現在アクティブに使用されていない情報は離れた場所(リモートストレージやディスク)に格納できる仕組みです。課題は、Atomspaceの知識ベースにおける独特な局所性の概念が、従来のデータベースエンジンがキャッシュと負荷分散ポリシーを実装する際に前提としている時間的、空間的な概念とは異なる点にあります。この不一致は、OpenCog Hyperonの環境において著しい性能低下を引き起こす可能性があります。
最初の課題に対処するため、DASは永続的なバックエンドで複数のデータベースエンジンを使用します。図2のように、これらのエンジンのAPIを抽象化し、利用可能なインデックスに応じてより適切なエンジンにリクエストをルーティングするレイヤーを実装しています。知識ベースの一部(例:ノードとリンクのプロパティ)はドキュメントデータベースでモデリングされ、他の部分(例:ハイパーグラフのトポロジー)はキーバリュー型データベースでモデリングされます。概念実証の実装ではMongoDBとRedisを使用していますが、他にも利用可能なデータベースエンジンが存在する可能性があります。
永続レイヤーへの要求は、1つ以上のデータベースエンジンにルーティングされます。具体的には、特定のノードの流入集合(特定のノードを指すリンク)に関する要求はRedisにリダイレクトされ、名前が指定された正規表現に一致するノードに関する要求はMongoDBにリダイレクトされます。この選択は、各データベースエンジンの利用可能なインデックスに基づいて、アトムDB内部で行われます。
DASは、MeTTaインタプリタ内で動作するローカルキャッシュを備えています。これは、ハイパーグラフの走査やサブグラフのパターンマッチングによって、アトムの作成、変更、検索を行うためのAPIを持つAtomSpaceです。このAtomSpaceは、MeTTaプログラマにとってAPI呼び出しが透過的に行われるように、インタプリタと統合されています。キャッシュポリシーは、実行時にサブグラフパターンを使用して定義され、アトムがローカルキャッシュからメインのDASサーバーへ、またはその逆方向にどのように移動するのかを決定します。
図2に示すように、DASの概念実証実装が開発されました。この実装は独立したコンポーネントとして作成され、Redisが3台、MongoDBが1台、DASが1台の計5台のサーバークラスタにデプロイされました。知識ベースには3億アトムが含まれており、ローカルで単純なAIアルゴリズムをローカルで実行してテストされました。通常のクエリに対するレスポンスタイムは良好な結果が得られたため、現在ではこれをMeTTaインタプリタに統合された本格的なHyperonコンポーネントにすることを目指しています。基本的な計画は以下の通りです。
- MeTTaインタプリタ内蔵のローカルキャッシュの実装:MeTTaインタプリタ内部で実行されるローカルキャッシュを実装します。このキャッシュポリシーは、関連するサブグラフパターンに基づく動的なルールで制御されます。
- スケーラブルなデプロイメントアーキテクチャの実装:知識ベースのサイズとクエリ負荷に合わせて自動的にスケーリング可能なデプロイメントアーキテクチャを実装します
- アトムDBとデータベースエンジンの最適化:各データベースエンジンが提供するインデックスとクラスタリング機能を最大限に活用できるように、アトムDBとデータベースエンジンをチューニングします。
- DASクエリエンジンの拡張:HyperonのAIエージェントが必要とする全てのクエリタイプをサポートするようにDASクエリエンジンを拡張します。
3.4. ブロックチェーン統合による分散型デプロイメント
適切なブロックチェーン技術を統合することで、Hyperonインスタンスを世界中の多くのマシンに分散させることができ、単一の所有者や中央管理者が不要になります。これにより、関係者同士が完全な信頼関係を築いていなくても、異なるマシンで動作する複数のエージェント間の協調が可能になります。
ブロックチェーンインフラを活用する利点は多岐にわたります。これにより、分散型Hyperonシステムは、家庭用コンピューターやスマートフォンなどの空きリソース、専用のホームコンピューティングボックス、さらにはこれまで暗号通貨のマイニングに使用されてきたサーバーファームなど、幅広いコンピューティングリソースを利用できるようになります。また、ブロックチェーンインフラは設計上セキュアであり、初期段階のAIシステムを訓練し学習させるためにデータを提供した個人や団体の主権を尊重します。さらに、このようなシステムへのハードウェア、データ、教育的インタラクションの提供を促す革新的なトークン経済モデルの活用も可能にします。
ベン・ゲーツェルは次のように述べています。分散型インフラの活用は、AGIが人間レベルに近づくにつれて、単一の勢力が強力なAGIシステムに対する独裁的な権力を握るリスクを低下させます。ここでの核心的な直感は、インターネットやLinuxオペレーティングシステムのような分散型で参加者によって統治されるシステムは、現在のアメリカや中国のビッグテック企業などが提供する中央集権型のITシステムよりも、強力なAGIの連携と運用においてより優れたモデルを提供するということです。
現在、Hyperonアーキテクチャへの緊密な統合が計画されている主要な分散型ツールには、以下が含まれます。
- SingularityNETプロトコル:分散型AIエージェント間の連携に使用されます。
- NuNetプロトコル:AIエージェントの集団間での分散型コンピューティングリソースの使用を調整する分散型プロトコルです。
- Hypercycleレジャーレスブロックチェーンプロトコル:分散型ソフトウェアプロセス間の安全でスケーラブルな分散型通信を実現します。
- Rholang言語:分散型ネットワーク上でスマートコントラクトを効率的に実行する機能を備えています。
Hyperon自体は、これらのツールが一つもなくても完全に機能させることができます。ただし、その場合、従来通りの方法で集中型サーバーファームにデプロイする必要があり、セキュリティはファイアウォールなどの従来の仕組みで確保することになります。また、異なる個人や組織が部分的に所有する、統合認知ネットワークを運用するのは難しくなります。
Rholangには、Hyperonにおいて2つの特別な役割があります。1つ目は、MeTTaスクリプトの安全な分散実行を可能にすることと、2つ目は、MeTTaスクリプトを並列処理のインフラ上で効率的に実行できるようにすることです。
SingularityNETの最高製品責任者であるJan Horlingsは、これらの様々なツールがもたらす付加価値を次のようにまとめています。SingularityNETプラットフォームは、本質的にAIサービスの流通チャネルとして機能し、あらゆる種類のAI手法の開発者がトラストレスな環境でAPIコールを収益化できるようにします。公開後は、ユーザーは誰でも自由にAPIコールを開始でき、開発者は成功した呼び出しに応じてAGIXトークンを受け取ります。これは、余計な負担なく収益化できる仕組みです。Hyperonは、このプラットフォーム上で多くの小規模で特化したAIサービスや知識グラフと並んで、非常に洗練された汎用的なAIサービスとして機能します。
Hyperonは、LLM、ECAN、PLN、SISTERなど、高度に統合された様々なAI戦略や機能を搭載してプラットフォーム上で提供します。しかし、Hyperonフレームワークは、さらに広範な種類のサービスを統合する機会が用意されています。この分散型プラットフォームは、Hyperonの機能拡張に参加したい開発者や組織にその機会を提供します。言い換えると、Hyperonとの統合により、独自のサービスを拡張することも可能なのです。
Hyperonとプラットフォーム上のサービスとの間のダイナミックな連携を可能にする重要な要素が、AI-DSL(AIドメイン固有言語)と呼ばれるものです。これは高度なインテリジェントサービスオーケストレーターであり、各サービスの入力、出力、目的だけでなく、多面的な評価スコアのような他の属性も認識します。AI-DSLは、利用可能なサービスとユーザーリクエストに基づいて、自動的にアドホックなワークフローを作成することができます。さらに、AI-DSLをLLMで強化することで、AIユーザーは自然言語でプラットフォームに指示を出すことが可能になります。この機能は「プラットフォームアシスタント」と呼ばれ、利用可能なサービスの中からユースケースやユーザーの特定のニーズに応じて、最適なもの(最速、最安価、最高品質など)と最適な順序を見つけ出し、自動的に望ましい結果を達成するための最適なシーケンスを導き出します。
言い換えると、プラットフォーム上で十分に成熟したHyperonが稼働すると、プラットフォームアシスタント(AI-DSL)は、Hyperonやその他の専用サービスに対するユーザーインターフェースとして機能します。もちろん、これは専用サービスやHyperonをプラットフォーム上で実行させる方法はこれだけではありません。あらゆる種類のツールやアプリケーションは、Hyperonや特定のサービスと直接連携することもできますし、APIベースのAI-DSLを活用して、プラットフォーム上のAIサービスエコシステムを継続的に監視し、特定のタイミングで最適なシーケンスを導き出すこともできます。
このようにして、プラットフォームはHyperonをオープンで完全に分散化されたエコシステムにしっかりと組み込みます。このエコシステムは、潜在的に非常に多様な知識グラフとAIサービスで構成されており、世界中の開発者コミュニティがHyperonのコア機能に貢献し、強化することを可能にします。同様に、誰もがHyperonに接続し、その成長する可能性から恩恵を受けることができます。
Hyperonとこれらの分散化志向ツールとの統合に関する基本戦略は比較的単純です。各DASコンポーネントと、MeTTaインタープリタを組み合わせたローカルなAtomSpaceは、SingularityNETエージェントとして扱われ、それらはNuNetノードと関連付けられたHypercycle AIマシンコンテナにラップされます。NuNetノードは、これらのエージェントの展開とオーケストレーションを管理します。これらのHyperonエージェントの1つで実行されているMeTTaスクリプトは、ネットワーク内の他のエージェントと対話する必要がある場合、Rholangにコンパイルされ、RholangのHyperCycleとの統合機能を利用して、他のエージェントとの安全なメッセージングを行います。
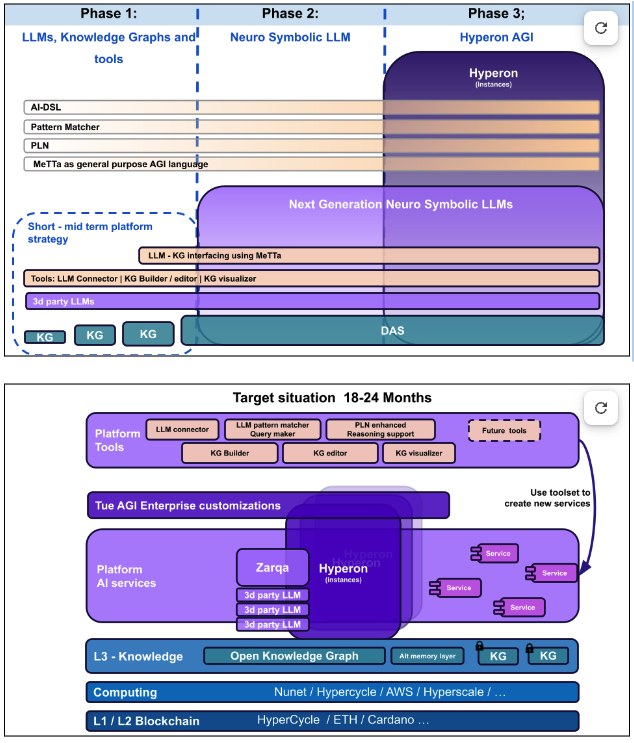
もちろん、これらすべての実装には多くの複雑な側面が関与し、2023年から2025年にかけて段階的に各種関連するツールがアルファ版からベータ版、そして完全な本番稼働バージョンへと移行していく中で、徐々に進められていきます。Hyperonの成熟と並行して、SingularityNETエコシステムの様々なインフラ構築ツールも急速に構築が進められています。図3の2024年のSingularityNETのプラットフォーム戦略は、特に特定のドメインをカバーする知識グラフの分散型ホスティングと活用(LLM、初期のHyperonバージョン、その他のAIツール内)に焦点を当て、Hyperonが成熟するにつれて、分散型Hyperonインスタンスに「プラグイン」として統合されるAIサービスの分散型ホスティングと相互接続に移行していく計画です。シンギュラリティネット財団から派生した垂直市場特化型プロジェクト、DeFi領域のSingularityDAO、長寿領域のRejuve Network、メディア領域のMindplexなどは、SingularityNET、Hyperon、NuNetインフラ上で適切なHyperonプラグインエージェントを提供することで、それぞれのビジネスモデルの一部を実現していく予定です。
3.5 MeTTaをRholangにコンパイルして迅速で安全な分散型実行を実現する
Hyperonのインフラと形式主義における新たな進展として、MeTTaをRholang(ローラン)言語にコンパイルするプロジェクトが推進されています。このプロジェクトは、以下の2つの目的を達成することを目指しています。
- 適切なハードウェア上でMeTTaプログラムの効率的な並列実行を実現する
- MeTTaをHyperCycleのレジャーレスブロックチェーン(および潜在的には他のチェーン)におけるスマートコントラクト言語として活用する
必ずしも、後者のアプリケーションであるMeTTaのスマートコントラクト言語への適用は、AGI言語としての利用と密接に関係するわけではありません。しかし、前述の通り、MeTTaプログラミング言語はAGI領域を超えて、幅広い適用可能性を有する独自の利点や特性を備えています。例えば、MeTTaを用いてレジャーレスDeFiのスマートコントラクトを記述することは、AGIやAIの有無に関わらず理にかなっています。なぜなら、MeTTaは形式的検証と効率的な実行に適しており、どちらもDeFi分野において重要視される要素だからです。
しかし、Hyperonシステム内でMeTTaをAIスクリプトやAI生成コードの記述に利用しつつ、Hyperonが組み込まれたHyperCycleネットワークのスクリプト操作にも利用する二重活用には、明らかに相乗効果の可能性が秘められています。このアプローチは、分散型ネットワークレベルで大規模な創発知能を備えた分散型AIシステムを開発する上で、大きな可能性を持っています。
MeTTaとRholangのインターフェースプロジェクトは、SingularityNET、Hyperon、Lucius Greg Meredith、および彼の前プロジェクトであるRChainの後継企業にあたるF1REFL3Yとの協力によって進められています。RChainは革新的なブロックチェーン技術を開発しました。その中心となるのがRholangスマートコントラクト言語です。Rholangは、Meredithが考案したロー計算(ρ計算)と呼ばれる数学体系の構文フロントエンドであり、並行計算プロセスの形式化において新たな領域を切り拓く革新的なものです。
Rholangは、分散環境や並列ハードウェア上で安全かつ効率的に実行できる注目すべき特性を持っています。2023年には、MeredithとそのチームがMeTTaからRholangへのソースコード変換コンパイラを開発しました。このコンパイラの目的は、MeTTaから生成されたコードにRholangと同等の並列処理とセキュリティの利点を付与することです。
Meredithは、この取り組みの重要なポイントを次のようにまとめています。AIを分散化するには、ブロックチェーンの特性を多く取り入れる必要があります。具体的には、LLMや定理証明機などのAIリソースを実行するノードは、DoS攻撃に対して耐性を持つ必要があります。さらに、そのようなリソースで構成されるネットワークは、個々のノードが故障しても耐えられるようにする必要があります。これが、SingularityNETのMeTTa言語をF1R3FLY.ioのRNodeに統合する動機の一つです。
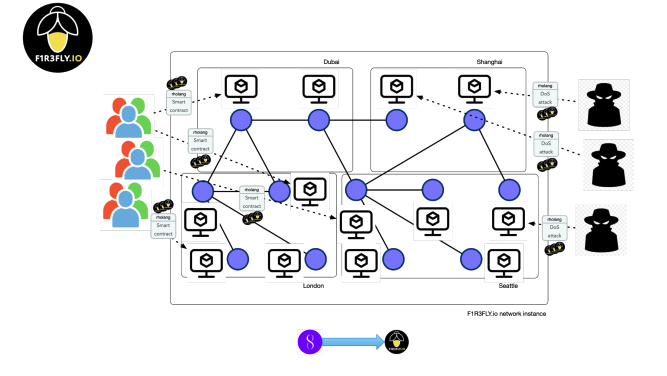
これらのRNodeはHypercycleを含む複数のブロックチェーンインフラと連携して動作する可能性があります。
もう一つの理由は、パフォーマンスです。現時点でのRNodeのパフォーマンスは、1ノードあたりの1プロセッサで約1,000トランザクション/秒(tps)のスループットを実現しています。ここで言うトランザクションとは、データが提供者から利用者にコミットされ、永続的に通信されることを指します。この実行モデルは、RSpaceと呼ばれる革新的なキーバリュー型データベース(KVDB)を用いて実装されています。RSpaceの大きな特徴は、データだけでなく、処理が中断した時点の情報(継続状態)もキーとして格納される点にあります。実行メカニズムは、Rholangと呼ばれるスマートコントラクトプログラミング言語で記述されています。MeTTa2Rhoコンパイラは、MeTTa言語をRholangに変換するプログラムです。このコンパイラを使用することで、ネットワークにノードが追加され、プロセッサが追加されると、rholangの実行がスケールするため、MeTTaの実行もスケーラブルになります。しかし、MeTTaをRholangにコンパイルするメリットはスケーリングだけにとどまりません。
実際、RNodeネットワークはすべてCBC-Casperと呼ばれるコンセンサスアルゴリズムに基づいて動作しています。これにより、すべてのノードが同じ実行状態のコピーを持つことが保証されるため、1つまたは複数のノードが故障しても、ネットワークは運用を続けることができます。さらに、ノードがRholangを実行するためには、クライアントがネットワークに紐づけられたトークンを使用し、計算とストレージリソースに対する費用を支払う必要があります。これは、必然的にDoS攻撃に対する予防策となります。
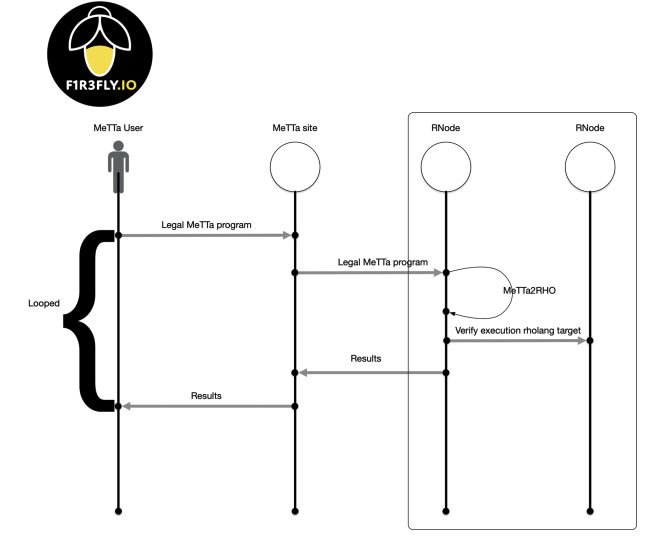
図4は、この処理の流れを概説しています。Meredithは次のように説明しています。図のように、MeTTaクライアント(人間ユーザーまたは計算エージェント)は正当なMeTTaプログラムをシステムに送信します。このバージョンでは、最初にゲートウェイを経由してネットワーク内のノードに転送されることを想定しています。ただし、ユーザーが直接プログラムをノードに送信することも問題ありません。これらのノードは、MeTTa2RHOコンパイラを搭載した改良型のRNodeです。コンパイラは、MeTTaプログラムをRholangに変換し、その後ノード上で実行されます。
本番環境での実装では、生成された実行ログは、ネットワーク内の他のすべてのノードによって検証されます。結果がある場合は、検証フェーズの終了後にユーザーに安全に伝達されるか、またはターゲットノードによるRholangの実行終了時に楽観的に(検証を待たずに)伝達することができます。
図5は、RNodeネットワークの概要を大まかに示しています。Meredithによると、RNodeネットワーク(シャードと呼ばれることも多い)は、世界各地に分散配置されたノードで構成されます。具体的には、AWS 米国西部リージョン、Google Cloud 英国リージョン、IBM Cloud EUなどにノードが配置されています。これらのノードは、KademliaとCBC-Casperを組み合わせた仕組みで相互接続されています。クライアントは実行要求に署名し、この署名は、Rholangの実行に必要な計算とストレージに関連するトークンを十分に持つウォレットを特定するために使用されます。
MeTTaからRholangへのコンパイラの開発については、論文『Meta-MeTTa:MeTTaのセマンティクス規則:Meta-MeTTa:An operational semantics for MeTTa』で詳しく解説されています。詳細は複雑ですが、基本的な仕組みは比較的シンプルです。具体的には、MeTTaのセマンティクスはレジスタマシンで定義されており、このレジスタマシンはCorrectness-by-Construction(CbC)と呼ばれる設計パターンを用いることで、容易にRholangにコンパイルできます。
このコンパイラを作成するプロセスは、MeTTa自体の機能セットを形作る上でも価値がありました。 具体的には、以下の2つの機能が挙げられます。
- 封印された項(Sealed terms):将来のMeTTaバージョンでは、望ましくない情報漏洩を防ぐため、外部からの調査に対して項を封印する手段がサポートされます。
- 内包表記(Comprehensions):将来のMeTTaバージョンでは、信頼境界を越えたリソースとの安全な通信を可能にするため、内包表記と呼ばれる概念がサポートされます。
これら2つの機能は、いずれもF1REFL3Yとのコラボレーションの結果としてMeTTaに追加されたものであり、どちらもスマートコントラクトアプリケーション以外の用途においても有用な可能性を秘めています。例えば、内包表記はMeTTaレベルでPLNのセマンティクスを簡単に表現する方法を提供します。
3.6 認知型AGI研究開発プラットフォームの必要性
Hyperonプラットフォームのアーキテクチャを構築する過程では、多くの困難で複雑な決断が伴いました。現在のHyperonシステムが唯一無二のアプローチだと主張するつもりは全くありません。しかしながら、現在存在する他のシステムや、我々が把握している他の開発中のシステムと比較して、Hyperonには大きな優位性があると確信しています。Alexey Potapovは、現在のAI分野の進化段階において、認知型AGI研究開発プラットフォームの必要性を強調しています。まず、彼は関連するLLMの限界を以下のように要約しています。
ここ10年間、深層学習は様々な分野で画期的な成果を挙げてきました。最近のLLMによる成果は、AGI実現への大きな可能性を感じさせます。しかしながら、LLMには記憶や世界モデルの欠如といった明らかな課題も存在しており、これらの限界を克服すべく、ニューロシンボリック統合によるシンボリック手法の活用が進められています。
ChatGPTやLLaMAのようなLLM上には、Langchain、AutoGPT、Voyagerなど、多数のラッパーが存在します。これらは、専用ソフトウェアとして、命令型プログラミング言語で書かれており、LLMを制御するためのさまざまな手法を実装しています。しかし、これには相互運用性がないという課題があります。このようなラッパーが必要とされるのは、LLMが一種の「言語反射」と呼ばれる仕組みを持つためです。言語反射とは、あらかじめ定められたパターンに基づいて、入力に対して自動的に出力を生成する仕組みです。LLMはこの言語反射の性質を持つため、特定の実用アプリケーションにおいて、シンボリックな制御によって精度や効率を向上させることができます。
LLMをAGIの候補として考えてみましょう。LLMにチェスをプレイさせたいとします。LLMはどのようにこれを行うのでしょうか?最善を尽くしても、外部プログラムであるMuZeroの呼び出しを生成するだけでしょう。しかし、LLMはMuZeroの一手一手を制御できるでしょうか?答えはノーです。LLMは現在のチェス盤の状況すら理解できません。さらに、チェスをプレイさせるだけでなく、LLMにルークでのチェックメイトを指示した場合、この情報をMuZeroにどのように伝えるでしょうか?そもそも、MuZeroはそのような情報を独自に考慮することができるでしょうか?答えは、何らかの変更や再訓練なしでは不可能です。
次に、LLMに2つのチェス盤で同時にプレイさせ、同じターンに両方の盤で同じタイプの駒を使うよう指示してみましょう。これを行うには、2つのMuZeroインスタンスをそれぞれのターンで連携して調整すべきでしょうか?答えはイエスですが、現状のLLMにはそれができません。LLMはゲームの状況やMuZeroの内部プロセスを理解していないため、連携させることはできません。このようなタスクをAGIシステムが遂行するためには、言語を含む世界のさまざまな側面に対する共有表現と、それに基づいた統合的な意思決定や行動選択プロセスが必要となります。
深層学習の支持者は、膨大な実世界のデータをすべて使って巨大なDNNを訓練すれば、自動的に世界表現とそれを活用するための戦略を学習できると主張するでしょう。実現可能性はさておき、そのようなアプローチは現時点で利用可能な計算リソースやデータ量を遥かに超える規模です。一方、ニューロシンボリック認知アーキテクチャにおけるシンボリック系の能力は、まだ十分に活用されておらず、探求の余地が大いに残されています。
LLMは既に、異なるパラダイムのAI手法を統合するための簡易的なハブとして活用され始めています。これらの手法は、それぞれ異なる思考様式に基づいており、LLMプラグインとして実装されています。しかし、プロンプトと呼ばれるブラックボックス的な浅い統合には限界があります。より認知的に豊かなアーキテクチャであれば、異なるAIパラダイムの手法をより巧妙かつ強力に組み合わせることが可能になります。Potapovは、「AIにおける様々なパラダイムや手法は偶然生まれたのではありません。それぞれに長所と短所があります。LLMもまた、異なる外部ツールとの迅速な統合が進んでいます。なぜなら、異なる分野の問題解決には、それぞれ適した手段を用いる方が効率的だからです」と指摘しています。
Hyperonは、異なるパラダイム間の完全な相互運用を目指しています。そのコアオペレーションは、汎用的な方法でストレージから情報を取得することです。この操作は、(メタ)グラフ知識ベースへのクエリ、関数型プログラミングにおけるパターンマッチング、論理推論における統一、さらにはTransformerネットワークやその他のニューラルモジュールにおけるアテンションヘッドによる処理にまで対応します。このような操作を連鎖させることで、 チューリング完全な言語を構築することができます。この言語は「認知的アセンブラ」として機能し、宣言型メモリと手続き型メモリ、エピソード記憶とセマンティック記憶、そしてこれらの記憶内での様々な情報処理形式を実装するための汎用的なアプローチとなります。
異なるタイプのストレージを同時に利用し、それらへの問い合わせを組み合わせることができます。デフォルトでは、シンボリッククエリを備えたメタグラフ知識ベース「Atomspace」が使用されますが、Atomspaceはサブシンボリック要素も含めることができます。ただし、高次元ベクトル、グラフ埋め込み、アテンションメカニズム、あるいは単なるプロンプトベース検索など、完全にニューラルネットワークに基づくストレージ空間を使用することも可能です。クエリの連鎖は、ストレージ(認知的観点からは記憶)の内容自体によって記述されます。これにより、ストレージの実装方法と学習方法を柔軟に選択できます。その結果、宣言的推論のさまざまな戦略だけでなく、確率的プログラミング、遺伝的プログラミング、ニューラルモジュールネットワークなど、他の推論戦略も実装して組み合わせることが可能になります。例えば、ニューラルモジュールネットワークは、シンボリック推論によってリアルタイムで組み立てられるだけでなく、ニューラルモジュールネットワーク自体もシンボリック推論なしで自律的に組み立てられます。同様に、宣言的推論もシンボリックな実装だけでなく、ニューラルな実装も実現可能です。
Hyperonでは、いくつかの具体的なアイデアやAGI理論をモジュールとして実装することを想定していますが、AGIの研究開発は依然として広範な分野です。Hyperonは、まさにそのようなAGI研究開発専用のプラットフォームであり、異なるパラダイム、アプローチ、手法間の認知的シナジーに焦点を当てています。この点が、特定の理論を中心に構築され、その理論の枠を超えたAGI研究開発には使いづらい他のプロトAGIシステムとは一線を画します。
Hyperonは、強力なシンボリック表現とニューラルネットワークを組み合わせた、複数のパラダイム間で相互運用可能なコンポーネントを段階的に開発することを可能にします。これは、従来のDNN中心のアプローチが非常に弱いシンボリックなオーバーレイを使用し、高度なシンボリックシステムがDNNと浅いレベルで統合されているのとは対照的です。Hyperonは、単なる研究やプロトタイピングのためのプラットフォームではなく、具体的なAGIシステムの開発のための有望なフレームワークにもなります。もし、複数のパラダイムを統合するアプローチが単一のパラダイムよりも効率的であるならば、Hyperonは今後のリーディングAGIプラットフォームになる可能性を秘めています。
<後編へ続く>
【よく読まれる人気記事】
カルダノステークプール【OBS】
暗号通貨革命では、カルダノステークプール(ティッカー:OBS)を運営すると共に、皆様に役立つ有益な情報を無償で提供して行きます。ADAステーキングを通しての長期的なメディア&プール支援のご協力の程、何卒よろしくお願い致します。

